Die Trefferliste neu denken: Digitalisierte Sammlungen im StabiKat Discovery
Mit dem letzten Update unseres Discovery-Systems haben wir Funktionen für die Trefferliste eingeführt, die so weltweit in keinem mir bekannten Discovery-System umgesetzt wurden.
Aber vielleicht greift das etwas zu kurz – irgendjemand muss ja anfangen mit den guten Ideen. Darum hier ein Einblick, warum wir diesen Ansatz gewählt haben, und warum wir ihn für wegweisend halten.
15 Jahre in der Mache
Ein Nachweissystem für den Kulturbereich neu denken: das war der Auftrag einer Arbeitsgruppe aus Expert:innen, die sich 2008 in den Anfangstagen der DDB – Deutsche Digitale Bibliothek – zwei Tage lang getroffen haben. Es waren damals bekannte Vertreter:innen (ich glaube es waren wirklich mehr Frauen als Männer) von Bibliotheken, Archiven und Museen vertreten, insgesamt ca. 15 Personen. Am Ende stand ein 10-Seiten Konzeptpapier, das wir als Grundlage für die anstehende Entwicklung der DDB empfahlen.
Es kam dann – sehr anders. Praktisch nichts davon wurde von Fraunhofer zum Start umgesetzt. Die Probleme der Datenzusammenführung der unzähligen Kultureinrichtungen waren auch so vielfältig, dass niemand Zeit hatte, sich um die Nutzeroberfläche oder erweiterte Funktionen zu kümmern.
Das Konzept sah aber einen wirklich interessanten Ansatz für Trefferlisten vor, zu finden auf den Seiten 7 und 8:

Diese Herangehensweise würden wir heutzutage in der User-Experience (UX) und User-Interface (UI) Gestaltung als “Accordion Interface ”, “Expandable Lists”, “In-Place Expansion” oder “In-Line Expansion” bezeichnen.
Die Besonderheit dieser Methode liegt darin, dass beim Klicken auf ein Suchergebnis ein Bereich direkt unter dem jeweiligen Treffer aufgeschoben wird, um zusätzliche Informationen anzuzeigen. Dieser “In-Place Detail View” sorgt für eine intuitive und flüssige Nutzererfahrung, indem er die Notwendigkeit umgeht, zwischen der Trefferliste und separaten Detailseiten hin und her zu wechseln. Das Ergebnis ist eine nahtlose Integration von Detailinformationen in den Suchkontext, wodurch die Benutzer:innen effizienter und zielgerichteter auf die benötigten Informationen zugreifen können und bei der Suche in einem kontinuierlichen Fluss bleiben.
Ich habe eine Arbeitsthese, warum dieser Ansatz bisher so geringe Verbreitung fand: es liegt ein Missverständnis vor. Alle wollen es immer so machen wie Google, denn nur das garantiert Erfolgt. Dabei wird vergessen, dass Google ein anderer Use-Case zugrunde liegt: ein Klick auf einen Treffer der Trefferliste öffnet keine Detailansicht, sondern eben die referenzierte Webseite. Unsere Use-Cases sehen aber anders aus: (leider) selten können wir auf ein Objekt referenzieren sondern präsentieren nur weitere Informationen über das Objekt, eben unsere Metadaten.
15 Jahre lag diese Idee im Schreibtisch. Im alten Stabikat war so etwas technisch unmöglich umsetzbar, ebenso beim zwischenzeitlich eingekauften EBSCO-Discovery. Mit unserer eigenen VuFind Installation hingegen schien es plötzlich realisierbar.
User Stories
In Suchsystemen unterteilen wir grob zwei Suchstrategien:
- Known Item Search
Ich weiß relativ genau, welches Werk ich suche. Ich möchte direkt sehen, ob es im Bestand ist und wie ich darauf zugreifen kann (Lesesaal, Ausleihe, Online Zugang, Download) - Exploratory Search
Ich bin auf der Suche nach Informationen zu einem Thema oder einer Fragestellung, ohne ein spezifisches Ziel oder einen spezifischen Artikel im Sinn zu haben.
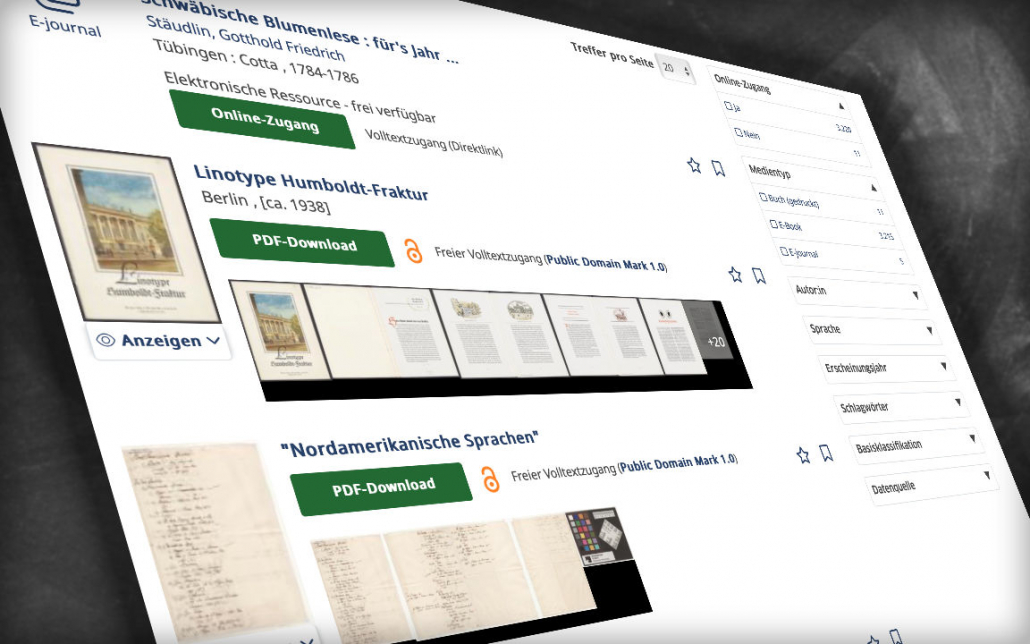
In unseren beiden Scrum-Entwicklungssprints zur besseren Einbindung der Digitalisierten Sammlungen in das Discovery haben wir beide Szenarien beachtet und versucht, möglichst kompromisslose Lösungen anzubieten. Kompromisslos meint hier: wir orientieren uns nicht an dem, was wir vielleicht gerne für die Deutsche Bibliotheksstatistik (DBS) hätten – lange Verweilzeiten, viele Klicks, Weiterleitungen in andere unserer Systeme für noch mehr Klicks – sondern an dem, was die Nutzenden maximal zufrieden macht. Ein Beispiel für die Known Item Search: wir wissen aus unzähligen Rückmeldungen – was auch immer wir uns für interessante Präsentationen und Visualisierungen einfallen lassen, am Ende des Tages wollen die Leute vor allem eines: das Dokument als PDF auf dem eigenen Rechner. Entsprechend haben wir die benötigten Klicks für diese “customer journey” so radikal gekürzt wie möglich: der “Call to Action” Button ist bei Einträgen aus den Digitalisierten Sammlungen nun direkt – ein PDF-Download:
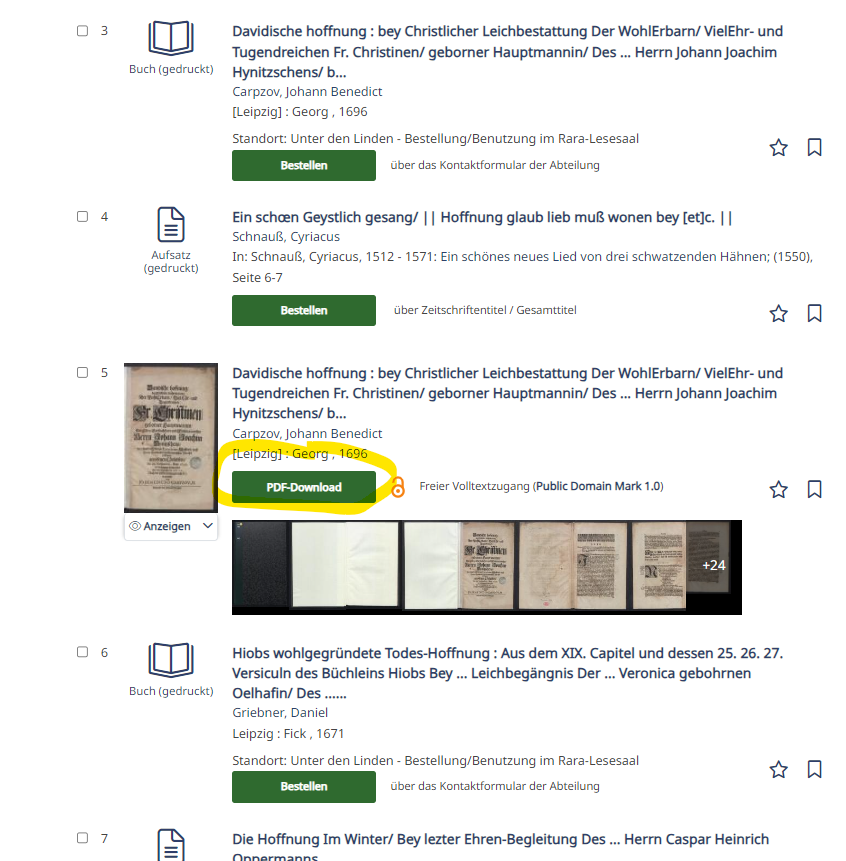
Wie hier schon zu sehen, unterscheidet sich der Treffer aus den Digitalisierten Sammlungen auch in anderer Hinsicht von den restlichen Treffern. Dies folgt Überlegungen für die Exploratory Search: “Ich weiß noch nicht, welche Werke mir wirklich helfen. Ich möchte die Trefferliste möglichst effizient durcharbeiten zu können um festzustellen, welche Titel für mich relevant sind”.
Aus dieser User-Story leitet sich für uns nun ein ganzer Strauß an neuen Features ab:
Features
Indexseite als Symbolbild
Die erste gescannte Seite eines Werkes ist nur selten interessant – zumeist ist es ein unbedruckter Einband. Wir zeichnen aber schon immer sogenannte Indexseiten aus bei der Erschließung unserer Digitalisate, eben die eigentliche Titelseite. Diese wird nun anstatt eines generischen Symbolbildes links in der Trefferliste angezeigt.
Perspektivisch lässt sich das auf viele andere Titel in unserem Bestand ausdehnen, das wäre ein sicher lohnendes Projekt für 2024.
Vorschauleiste der ersten Seiten
Schon wenige Seiten vermitteln einen guten Eindruck, um was für eine Art Werk es sich handelt. Die ersten acht Seiten werden daher schon in der normalen Trefferliste eingeblendet, zusammen mit der Information wie viele noch verborgen sind was einen schnellen Eindruck vom Umfang des Werkes gibt.
Thumbnailteppich aller Seiten
In einem physischen Buch kann man Blättern, um sich einen schnellen Überblick zu verschaffen. Im digitalen Bereich haben wir schon seit langer Zeit ein mindestens ebenbürtiges Werkzeug: den sogenannten “Thumbnailteppich”. Der wird häufig aber eher versteckt – vermutlich aus Performancegründen. Nicht so bei uns: ein Klick auf die Vorschauleiste gibt den Blick frei auf das komplette Werk – von der ersten bis zur letzten Seite. Ohne, dass wir die Trefferliste verlassen haben. Zusätzlich ist ein Hover-Effekt eingebaut, mit dem ich eine größere Vorschau erhalte – wiederum ohne einen eigenen Viewer zu bemühen. Damit lässt sich etwa schnell die Frage beantworten: in welchem Humboldt Tagebuch war noch einmal dieser große, blaue Fleck?
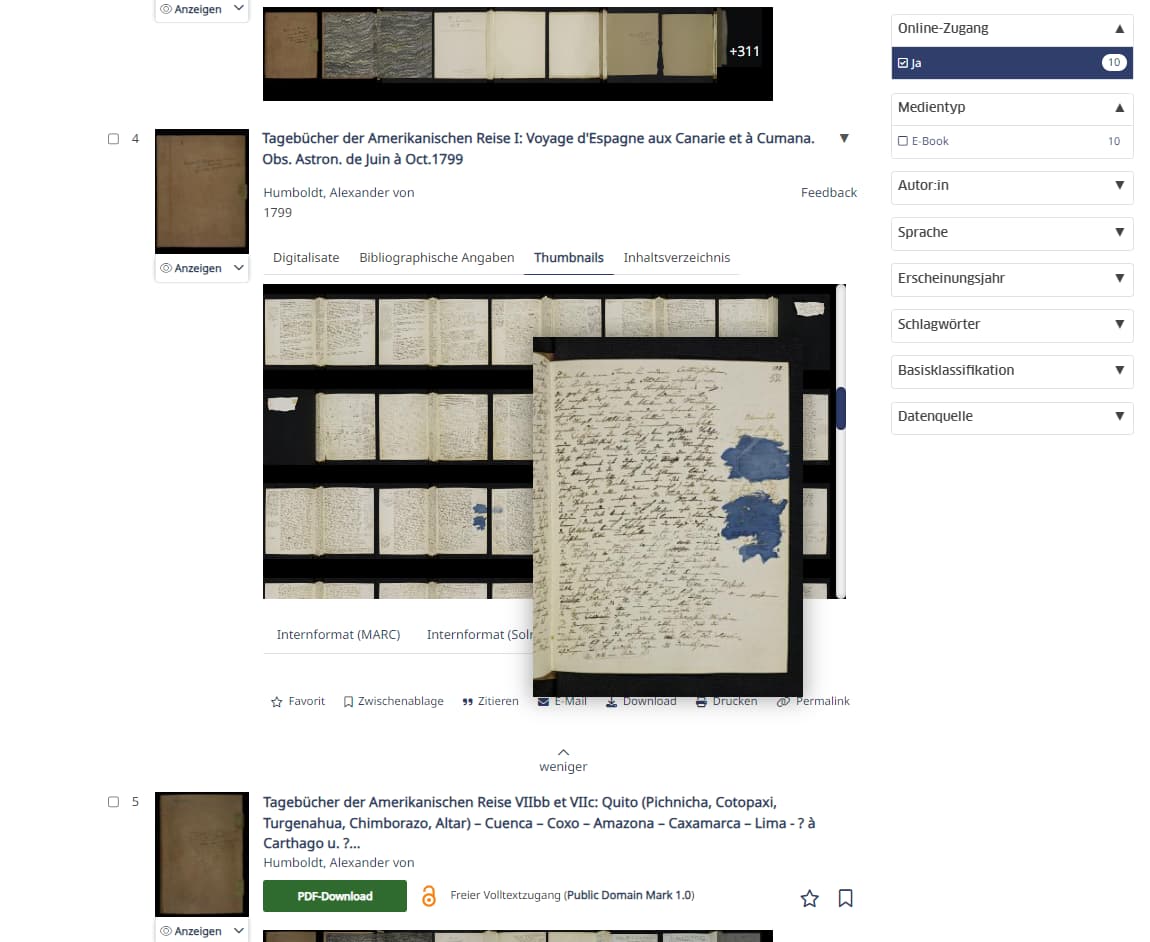
Seite aus Humboldt-Tagebuch
Inhaltsverzeichnis
Bei vielen Werken betreiben wir hohen Aufwand, um die Struktur und Inhaltsverzeichnisse händisch zu erfassen. Dieser Aufwand wird nun endlich im StabiKat sichtbar gemacht. Dabei ist das neue Inhaltsverzeichnis hoch funktional: eine Hover-Vorschau zeigt die erste Seite des jeweiligen Kapitels, man kann ein PDF des jeweiligen Abschnitts herunterladen und ein Klick führt in die Vollansicht:
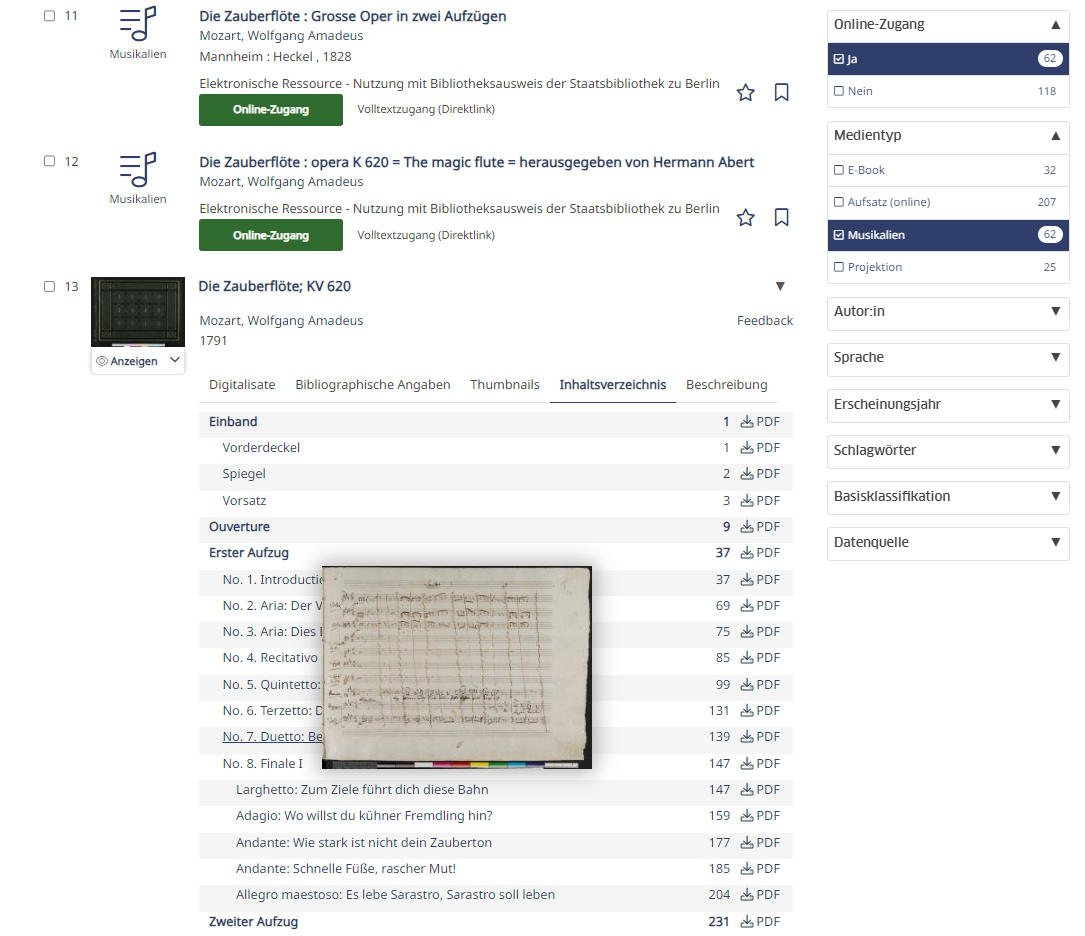
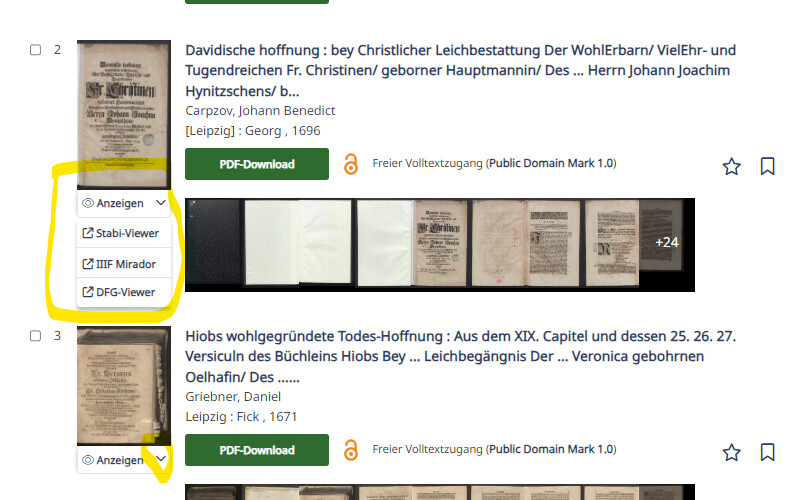
Freie Viewerwahl
Für einige Anwendungsfälle mag es immer noch sinnvoll sein, nicht das PDF zu nehmen sondern spezialisierte Viewer. Hier bieten wir gleichberechtigt an: unseren Stabi Viewer, iiif Mirador sowie den DFG-Viewer.
Technischer Hintergrund
Wir hatten nur zwei Entwicklungs-Sprints in IDM3 verfügbar: das entspricht sechs Wochen, dazu in der Ferienzeit. Um dennoch diese Funktionen anbieten zu können wurde eine sehr grundsätzliche Entscheidung getroffen: wir rühren den bestehenden K10+ Index beim GBV, also die Grundlage des StabiKat, nicht an. Die entsprechenden Abstimmungsprozesse hätten viel zu lange gedauert, und: waren für das zu erreichende Ziel auch nicht notwendig.
Stattdessen hatten wir eine sehr einfache, technische Idee.
Auf einer Trefferlistenseite haben wir: Zeit.
Solange die Liste grundsätzlich schnell aufgebaut ist, stört es nicht, wenn nach und nach weitere Informationen nachgeladen werden – die Nutzer:innen müssen sich in der Liste ohnehin erst orientieren. All unsere erweiterten Informationen werden also nachgeladen, sobald die eigentliche Trefferliste aus dem K10+ Index aufgebaut und angezeigt ist (Progressive Enhancement / Lazy Loading).
Das wurde nur möglich, da wir unsere Digitalisierten Sammlungen weitsichtig seit Jahren mit flexiblen und hochperformanten Schnittstellen ausgestattet haben – allen voran unser Content Server, der in der Lage ist sehr schnell Bilder in beliebiger Größe zu generieren, aber auch unsere METS/MODS Metadaten-Dateien auszuliefern oder iiif-Manifeste. Während also die Trefferliste aufgebaut wird, wird im Hintergrund unser Contentserver abgefragt der die zum Objekt passende METS/MODS Datei ausliefert. Aus dieser können wir mit einfachem XML-Parsing sowohl die Pfade etwa zu den Thumbnails als auch die Inhaltsverzeichnisse generieren.
Der StabiKat selbst wird durch dieses Verfahren kaum zusätzlich belastet, und unsere eigene Infrastruktur skaliert (noch) sehr gut.
Erfolgskontrolle
“Zahlengetriebene UX” ist ein neues Schlagwort in IDM3. Wir schauen uns also sehr genau in Matomo an, wie die neuen Funktionen von den Nutzenden angenommen werden – um im Zweifel weiter optimieren zu können. Wir sehen etwa schon nach zwei Tagen einen ersten Trend: von drei Personen entscheiden sich zwei, in die Digitalisierten Sammlungen zu wechseln, einer reicht jedoch schon der direkte PDF-Download im Discovery.
Einschränkungen
Die pragmatische Festlegung “wir fassen den K10+ nicht an” führt zu einigen Einschränkungen, die ich hier nicht verschweigen möchte:
- Da die nun eingeblendeten Informationen wie Inhaltsverzeichnisse oder erweiterte bibliographische Angaben nicht Teil des Index sind, kann nach ihnen auch noch nicht gesucht werden.
- Das Thema Volltext “ignorieren” wir derzeit komplett. Dieser macht u.E. auch nur auf Ebene des Index Sinn und wäre ein lohnendes Thema für 2024.
- Es gibt im Index leider keinen guten Schlüssel, mit dem man in unsere Facetten-Seitenleiste einen Schalter “in den Digitalisierten Sammlungen enthalten” einbauen könnte – die einzige Userstory, die wir nicht umsetzen konnten. Diese Suche bietet das zwar de facto, aber es ist eben keine Facette.
Ausblick und Feedback
Derzeit wird nur ein Teil unserer Discovery-Objekte – immerhin 210.000 – mit diesen neuen Funktionen erweitert. Grundsätzlich wäre es denkbar, und meines Erachtens auch wünschenswert, dies auf so viele der anderen Bestände wie möglich zu erweitern.
Das ist aber ein nicht unerheblicher technischer Aufwand, den man auch in andere Bereiche investieren könnte. Daher würde uns an dieser Stelle interessieren – wäre es das Wert? Sehen Sie hier einen praktischen Nutzen? Oder haben alle anderen Discovery-Anbieter doch Recht, und wir stampfen die Idee wieder für die nächsten 15 Jahre ein?
Ich freue mich auf einen regen Austausch!


Hab dann mal Smart Drag’n’Drop für STABIKAT und das Chronoscope World angeschaltet.
Video: https://norden.social/@chronohh/111488481356881464
Guide: https://mprove.de/chronoscope/guide/en/iiif.html
Ansonsten alles sehr richtige Überlegungen und Umsetzungen.
PDF halte ich für überschätzt. Das ist nur Symptombekämpfung seitens der Nutzer, da sie sonst die Schätze nicht wiederfinden.
Da sind wirklich viele gute Ideen sehr gut umgesetzt. Ich persönlich kann auf den PDF-Button verzichten, aber er scheint sehr nützlich für Leute die noch nicht im 21. Jahrhundert angekommen sind.