Beiträge zu Innovationen in unserem IT-Bereich
 SBB I Hagen Immel CC NC-BY-SA
SBB I Hagen Immel CC NC-BY-SA
Recap: VuFind® Berlin 2025 – What’s in it for us?
From September 29 to 30, 2025, the Berlin State Library hosted the international VuFind® Global Summit alongside the German VuFind® User Group Meeting. Under the motto What’s in it for us?, more than 120 participants – 60 on site in the library’s Simón-Bolívar-Saal and another 60 joining online – came together to discuss how discovery systems […]
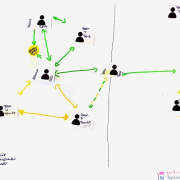 Copyright (c) Mark-Jan Bludau, Marian Dörk, SoNAR Team and contributors
Copyright (c) Mark-Jan Bludau, Marian Dörk, SoNAR Team and contributorsSoNAR: Bridging Cultural Heritage and Digital Research
Libraries, archives, and museums are treasure troves of information – not just about objects, books, and records, but also about the people behind them. Who created an artifact? Who published a text? How were individuals and organizations connected? These relationships form the backbone of our cultural heritage, helping us understand the context of creation, usage, […]

Call for Presentations – 8. Workshop Retrodigitalisierung „Digitalisierung für die Ewigkeit? – Datenqualität in der Praxis“
Der achte Workshop Retrodigitalisierung findet am 19. und 20. März 2026 in der Staatsbibliothek zu Berlin – Haus Unter den Linden in Berlin statt. Er richtet sich an Praktiker:innen, die sich in Bibliotheken mit der Retrodigitalisierung befassen. Wie in den Vorjahren bietet der Workshop ein breites Spektrum an interessanten Vorträgen zur Praxis der Retrodigitalisierung. Dafür […]

Unlock newspaper knowledge with CrossAsia’s AI Explorer: explore and test two new features for finding similar and possibly relevant articles across languages
Der CrossAsia Newspaper Explorer wurde um zwei neue KI-gestützte Funktionen erweitert, die es ermöglichen, ähnliche und relevante Zeitungsartikel über Sprach- und Schriftgrenzen hinweg zu finden. Die erste Funktion „Show results by similarity“ erweitert Suchergebnisse, indem sie semantisch ähnliche Artikel aus verschiedenen Quellen anzeigt, während die zweite Funktion „Cross-language search for similar titles“ von einem konkreten […]

VuFind® Berlin 2025: What’s in it for us?
VuFind® Global Summit & German VuFind®-Anwendertreffen Berlin State Library (and online) Potsdamer Straße 33 10785 Berlin Simón-Bolívar-Saal Theme: What’s in it for us? September 29 – 30, 2025 Download Timetable or full conference program Registration closed Please for questions. The Berlin State Library is happy to invite you to the VuFind® Berlin 2025 Conference on […]