
121 Million Chinese Characters Now Searchable in Our Digitized Collection: Full-Text Access Powered by OCR
Our collaboration with Academia Sinica (Taiwan) has recently reached a significant milestone. With generous support from the Center for Digital Cultures at the Academia Sinica, we are now able to provide full-text access to our digital Chinese collection. This includes 1,937 titles and over 121 million Chinese characters.
The partnership between the East Asia Department of the Staatsbibliothek zu Berlin (SBB) and Academia Sinica was officially established on July 16, 2024 (see our blogpost from that day), marked by a Memorandum of Understanding signed by both institutions. The agreement outlines our joint efforts in applying Optical Character Recognition (OCR) to Chinese image texts and sharing the results—including scanned images and machine-generated transcriptions—to support non-commercial digital humanities research, teaching, and public access in both Germany and Taiwan.
The OCR-processed texts come from the SBBs Early Chinese collection and include both printed works and manuscripts. The earliest acquisitions date predominantly from the 17th century and were initially made by the Great Elector Friedrich Wilhelm of Brandenburg (1620—1688) for his private library. The collection grew only sporadically until the 19th century, when the first systematic acquisition journeys began—initially by Karl Friedrich Neumann (1793–1870), and later in the early 20th century by Herbert Müller (1885–1966) and Friedrich Wilhelm Karl Müller (1863–1930).



The collection was further expanded through the purchase of private collections, including those of Friedrich Hirth (1845–1927), Paul Georg von Moellendorff (1847–1901), Eugen Pander (1854–1894), Erich Haenisch (1880–1966) — in the seventies —, and Paul U. Unschuld (1943-) – in 2012. Early titles were catalogued with Libri sin. shelfmarks; in 1912, the assignment of Libri sin. N.S. shelfmarks began. Altogether, there were 1603 Libri sin. shelf marks assigned to about 900 titles. Libri sin. N.S. 2049 is the last historical shelf mark of the New Collection and was assigned to a title published in 1935. The private collections were assigned individual shelf marks, like Libri sin. Hirth Ms., Slg. Moellendorff, Slg. Pander, and numerous current shelf marks for the Haenisch collection.
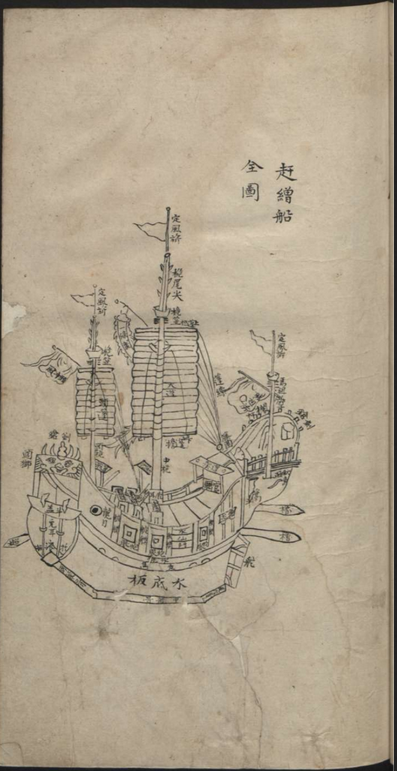
閩省水師各標鎮協營戰哨船隻圖說, Libri sin. Hirth ms. 5
In 1943, the East Asia Collection comprised about 72,000 volumes and was, at the time, one of the most important and largest collections of its kind in the Western world. Only about 24,000 volumes returned to the library which after the war found itself being situated in what by then had become part of the Soviet occupation zone. A small fraction of materials that went to Marburg were those holdings of the Staatsbibliothek which had been evacuated during the war to places that now were part of the Allies’ occupation zones. To a large extent, the old East Asia Collection is today considered destroyed or missing. Nearly one third of the old Collection – approximately 20,000 volumes – was located after the war on now Polish territory and was later transferred to the Biblioteka Jagiellońska in Kraków, where today it comprises a part of the so-called “Berlinka”. Between 2010 and 2014, the East Asia Department of the SBB digitized selected parts of its Berlin holdings, including the Libri sinici segment and the collection of the German sinologist Erich Haenisch.
In 2013, the virtual reconstruction of the former East Asia Collection was initiated, and the segments of the collection that, as a result of the Second World War, are now held in Kraków were almost completely digitized. The virtual reconstruction of the collection laid the basis for the recently and successfully implemented OCR project on the collection’s early Sinica.
After a year of collaborative work, the OCR results are now publicly available. Users can access the digitized Chinese collection with full-text OCR via our Digital Collections (“Digitalisierte Sammlungen”) portal: https://digital.staatsbibliothek-berlin.de/suche?category=Sinica. When viewing a scanned image, users can click the icon under “Full text” to see the automatically transcribed content.
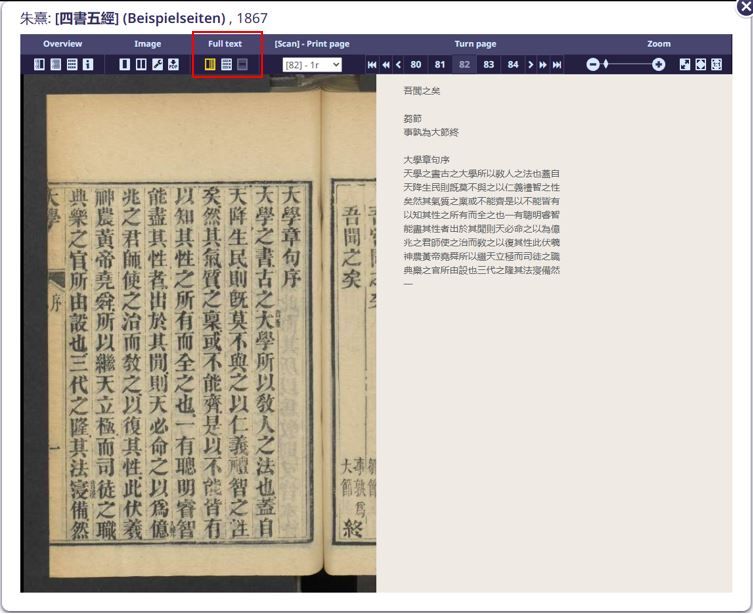
Example of the “Full text” feature on a scanned image
The transcribed texts are also integrated into the full-text search function. To search, simply enter a keyword into the search bar. For multi-character words, enclose them in quotation marks (e.g., „朱熹“) to ensure they are searched as a single term. Please note that full-text search currently supports Traditional Chinese only.
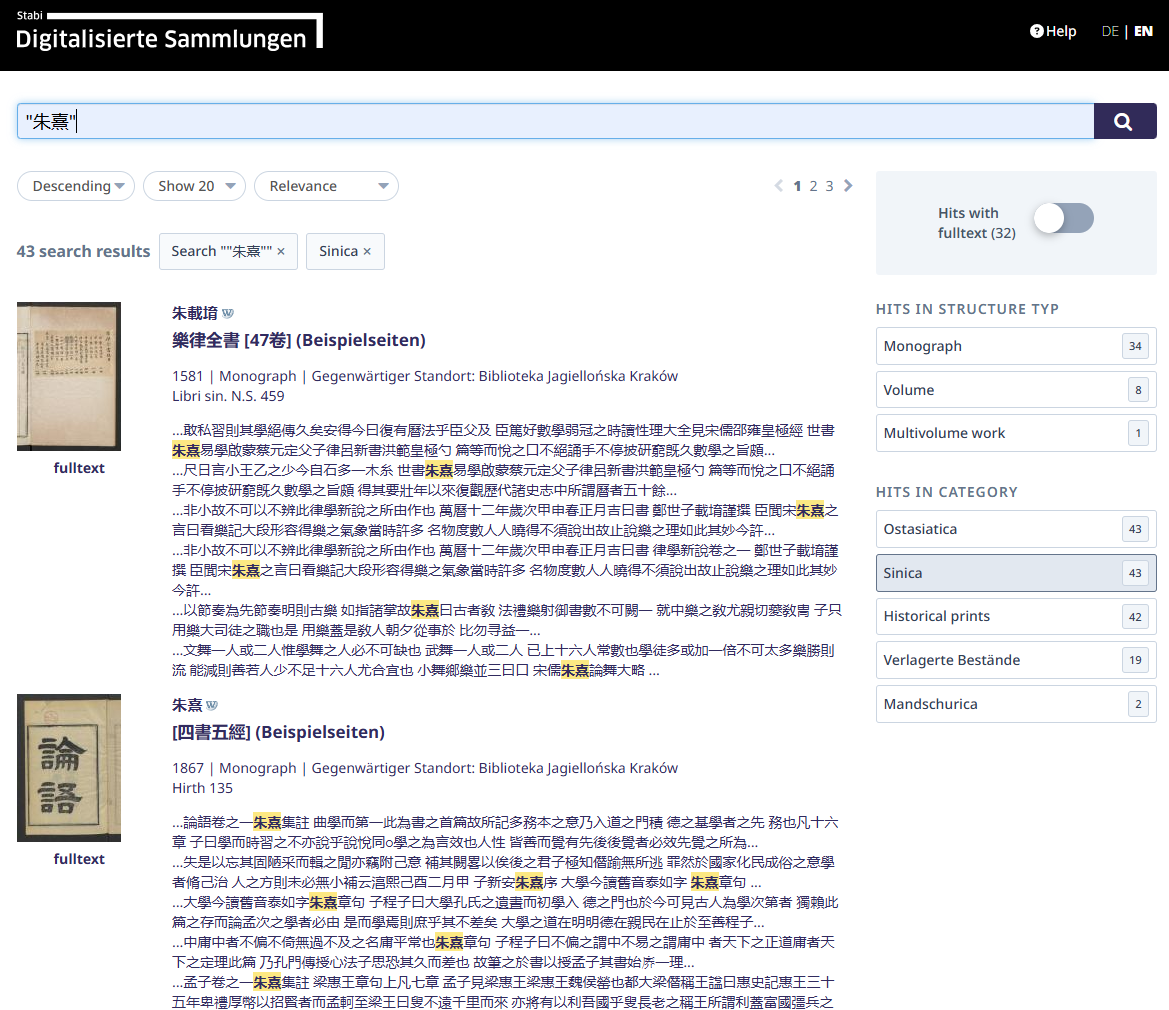
Example of a full-text search for „朱熹“ in the Digital Collections (“Digitalisierte Sammlungen”)
Alternatively, users can explore the data through the CrossAsia Fulltext Search (http://sbb.berlin/e6gqn): The tool supports Chinese hanzi (both simplified and traditional), Japanese kanji, and Korean hanja and does not require quotation marks when searching for words composed of multiple characters.
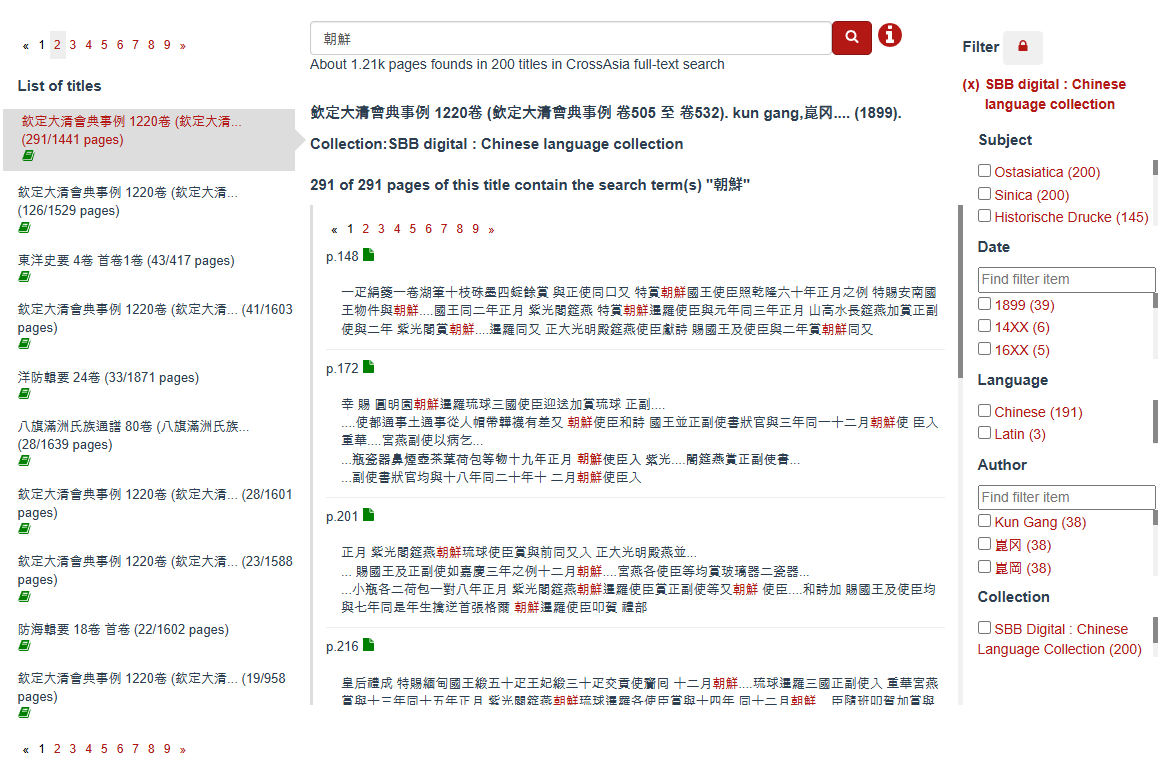
Example of a full-text search for „朝鮮“ in the CrossAsia Fulltext Search
In the platform of Digital Collections, users can also take advantage of the annotation feature in the viewer. In the top right corner of the image viewer, click the “arrow” icon to open the annotation tool. Using the Hypothes.is platform (login required), annotations can be made either publicly or within private groups. As the full-text content is generated automatically, some transcription errors are inevitable. We warmly invite users to help improve the OCR results by leaving comments via this annotation feature. Public annotations will be collected to guide future enhancements of OCR accuracy.
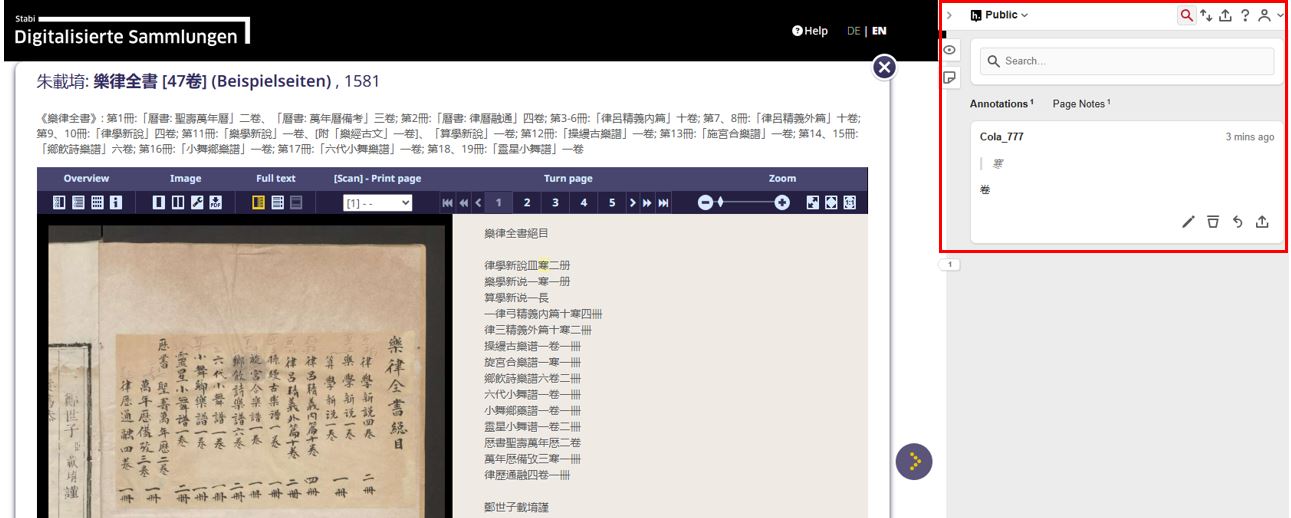
Annotation window in the digital viewer
We sincerely thank our colleagues at the Center for Digital Cultures, Academia Sinica, for their invaluable support throughout this collaboration. We look forward to continued cooperation to further enrich the digital resources available at both institutions. We also welcome feedback from users to help us improve the accuracy of OCR outputs and enhance the usability of the collection. Your input is essential to the ongoing development of this resource.
Yours,
CrossAsia Team

