
Zitationsbasierte Recherche im Stabikat
too long; didn’t read
- Im Stabikat sind mit der Normdatenverknüpfung und der Zitationsabfrage zwei neue Features verankert
- Vorschlagssysteme ergänzen den Suchschlitz um Recherchewege
- (auch) maschinelle Vorschlagssysteme bauen auf intellektueller Arbeit auf
- offene (Meta-)daten sind Voraussetzung für reproduzierbares wissenschaftliches Recherchieren
Suche und Vorschlag
Der Einstieg so gut wie jeder Recherche ist heute der Suchschlitz einer Webseite. Mit einigen Wortkombinationen ausgestattet gehen wir davon aus, dass uns passende Ergebnisse vorgelegt werden. Ob wir dafür genaue Werktitel eintippen, oder grobe Suchbegriffe, soll den Suchmaschinen egal sein. Sie sollen in der Lage sein, sowohl nach Relevanz zu sortieren, als auch außerhalb unserer Erwartungen liegende Treffer zu produzieren. Weil wir mit den Ergebnissen entsprechend häufig genug unzufrieden sind, bieten viele Suchmaschinen neben dem Suchschlitz auch Vorschlagssysteme an, die erlauben, Verknüpfungen nachzugehen, auf die unsere begriffliche Suche uns nicht gestoßen hätte.
Redundanz vs Varianz
Die Generierung von Treffern zu einer Suche lässt sich auf einer Skala von Redundanz zu Varianz einordnen. Während eine Suche mit Titel, Autor und Veröffentlichungsjahr auf eine möglichst redundante Suche zielt, sollen viele Rechercheanfragen möglichst auch solche Werke anzeigen, von denen man häufig noch nicht weiß, welche Schlagwörter ihnen zugewiesen sind. Suchprozesse sind nicht linear, und sogar der Zufall spielt in der wissenschaftlichen Erkenntnis weiter eine wichtige Rolle. Wo sich Ergebnisse auf diesem Spektrum anordnen ist aber nicht letztlich bestimmt durch die Intention der Suchenden, sondern durch die Algorithmen, die ihre Suche in Indexen strukturieren und Trefferlisten erstellen. Entsprechend versuchen Bibliotheken, ihre Systeme so zu entwickeln, dass sie Nutzenden beide Aspekte wissenschaftlicher Suche ermöglichen.
Katalog und Discovery
Mit dem Übergang vom Stabikat Classic zum Stabikat markierte auch die Staatsbibliothek den Wechsel von Katalog zu Discovery System. Diese Entwicklung, die derzeit viele Bibliotheken vollziehen, bringt neue Suchmechanismen mit sich. Sie zielt darauf ab, das jährlich enorm wachsende wissenschaftliche Publikationsaufkommen besser durchsuchbar zu machen, sprich: die Relevanz zwischen tausenden von Treffern zu gewichten. Dafür arbeiten Bibliothekar:innen und Entwickler:innen konstant an den Algorithmen, die von Titelangaben bis zu Zitationsbeziehungen die unterschiedlichsten Eigenschaften eines Dokumentes darauf abtasten, ob sie zu den eingegeben Zeichenfolgen passen.
Suchlogik und Empfehlungslogik
Der Katalog oder Online Public Access Catalog (OPAC) war und ist ein System, in dem Suchanfragen strikt nach einer Übereinstimmung der Suchtermini mit Schlagworten oder Titelsätzen geprüft werden werden. Die meisten Suchmaschinen, mit denen wir heute im Web konfrontiert sind, nehmen weiteren Kontext hinzu und personalisieren unsere Suchen: nach bisherigen Suchanfragen, nach bisher angeklickten Links und so weiter. Diese Kontextualisierung beruht nicht nur auf unseren Daten, sondern häufig auch auf denen anderer Suchender. So werden Suchvorgänge kollektiviert und die Suchräume engen sich ein: solche Ergebnisse, die der Mehrheit für nützlich gelten, schieben sich im Ranking nach oben. Für wissenschaftliche Suchmaschinen eine problematische Logik.
Auf Grundlage der gesamten analysierten Suchabfolgen werden aber nicht nur Suchergebnisse gerankt, häufig werden uns Vorschläge gezeigt: „Andere kauften auch…“. Vorschlagssysteme finden sich auf Musik- und Videoplattformen ebenso wie auf den Seiten von Webshops. Nutzendendaten sind dabei nicht die einzige Möglichkeit, große Datenbestände für Vorschlagssysteme auszuwerten. Auch bibliothekarische Discovery-Systeme nutzen Vorschlagssysteme: die Universitäts- und Stadtbibliothek Köln etwa schlägt ihren Nutzenden in der Detailansicht eines Werkes weitere Werke vor, die gemeinsam mit diesem in der Wikipedia zitiert werden. Hier besteht die Möglichkeit, Suchräume auszuweiten, ohne die komplexen und fein eingestellten Algorithmen anzugehen, die die Suchergebnisse und ihr (Relevanz-)Ranking produzieren.
Gerade die unterschiedlichen Logiken von Suche und Vorschlag machen in Kombination komplexe Suchwege möglich, die sich einer Vielzahl von Verknüpfungen bedienen.
Verknüpfungen im Stabikat
Auch im Stabikat werden deswegen Verknüpfungen ausgebaut – seit einigen Monaten steht bereits die Verknüpfung mit Normdatensätzen über lobid zur Verfügung. Über ein kleines „i“ können in der Detailansicht Fenster mit Verknüpfungen zu Datensätzen etwa von Autoren oder zu Schlagworten aufgerufen werden. Damit bietet der Stabikat einen Einstieg in die Recherche im Semantic Web. Über Sachverknüpfungen, die gemeinschaftlich (wie etwa bei der Wikipedia) und professionell (wie etwa bei der Deutschen Nationalbibliothek) gepflegt werden, kann man die Suche über ein weites Netz begrifflich definierter Verbindungen ausweiten.
Noch neuer ist die Verknüpfung von Titelsätzen mit dem Zitationsindex COCI. In der Detailanzeige eines gefundenen Titels aus der Datenquelle Crossref können jetzt per Klick solche Werke gefunden werden, die diesen Titel zitieren. Umgekehrt zur Zitationssuche über Literaturverzeichnisse kann hier also „flussabwärts“ nach neueren Titeln gesucht werden, die sich auf einen gefundenen Treffer beziehen.
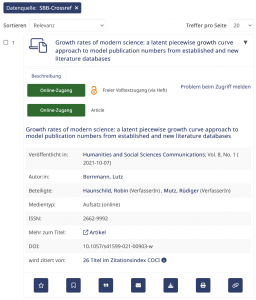 Per Klick auf die „26 Titel im Zitationsindex COCI“ wird die Liste zitierender Werke aufgerufen
Per Klick auf die „26 Titel im Zitationsindex COCI“ wird die Liste zitierender Werke aufgerufen
Zitationsbasierte Recherche
Mit der Zitationsabfrage über COCI per Klick in der Detailanzeige macht der Stabikat einen großen Schritt, der Rolle, die Zitate für Wissenschaft und wissenschaftliche Recherche spielen, gerecht zu werden. Häufig geht der Rechercheweg mangels technischer Lösungen immer noch über das Literaturverzeichnis als klassischem Nachweis. Mit Webtechnologien ist allerdings längst möglich, unterschiedlichste Arten von Zitation darzustellen und abzufragen: Ko-Zitation, also die gemeinsame Zitation zweier Autoren oder Werke in einem dritten Werk, oder bibliografische Kopplung, also die Verbindung zwischen zwei Werken, die gemeinsam ein drittes zitieren. Die aus diesen Verbindungen entstehenden Netze werden insbesondere in Forschungsfeldern, die sich schnell entwickeln, sehr unübersichtlich, was maschinenlesbare Formen der Zitation umso wichtiger werden lässt.
Zitationsindexe
COCI – der OpenCitations Index of Crossref open DOI-to-DOI citations erfasst, wie andere Zitationsindexe auch, Metadaten darüber, welche Werke von welchen Werken zitiert werden. Diese Indexe spielen vor allem in bibliografischen Studien, die etwa bestimmte Trends im wissenschaftlichen Publikationswesen analysieren, eine große Rolle. Ihr Nutzen auch für bibliothekarische Discoverysysteme wird jetzt unter anderem durch den Stabikat erprobt. COCI verbindet DOIs mit DOIs: diese „persistent Identifiers„, die Ressourcen wie beispielsweise Zeitschriftenartikel mit einer eindeutigen Webadresse versehen, sind deswegen ein wichtiger Baustein für das Netz von nachgewiesenen und maschinenlesbaren Zitationsbeziehungen. Da COCI die von Crossref vergebenen DOI und deren Zitationsbeziehungen verzeichnet, ist es für Treffer aus der Datenquelle „Crossref-SBB“ deutlich wahrscheinlicher, dass sie Zitationen nachweisen.
Möglich macht die Nutzung des Indexes die Tatsache, dass er, im Gegensatz insbesondere zu kommerziellen Indexen, offen ist, alle Beziehungen offen einsehbar und maschinell abfragbar sind sowie das gesamte Datenset strukturiert verfügbar ist: diese Metadaten offen verfügbar zu machen erforderte und erfordert andauernde Lobbyarbeit.
Openness in gemeinsamer Verantwortung
Empfehlungssysteme beruhen auf menschlicher, für Maschinen auswertbarer, Arbeit. Nutzungsdaten zum Beispiel, die zu „andere lesen“-Vorschlägen verarbeitet werden, machen sich die Suchergebnisse einer kollektiven Nutzerschaft zu eigen und verknüpfen statistisch, was Einzelpersonen sachlich möglicherweise nicht zusammengebracht hätten. Obwohl keine der so aggregierten Suchen als Beitrag zu besserer Recherche intendiert ist, geht doch ein Quäntchen intellektueller Arbeit aus dem Suchprozess in zukünftige Suchen ein.
Gepflegte semantische Netzwerke, wie etwa jenes, was die Deutsche Nationalbibliothek mit der Gemeinsamen Normdatei ausbaut, führen die Arbeitsprozesse wissenschaftlicher Bibliotheken in Klassifikation und Erfassung zusammen. So entstehen verlässliche, von öffentlicher Hand geprüfte und nachhaltig gepflegte Verknüpfungen zwischen Werken, Personen, Sachbegriffen und so weiter.
Auch Zitationsdaten müssen von Menschen erfasst werden, ganz basal während dem Prozess der Recherche und des wissenschaftlichen Schreibens, und in der Publikation durch die Anreicherung von Indexen mit Metadaten. Während allerdings gute wissenschaftliche Praxis ohne Zitieren gar nicht zu denken ist, ist das Zitieren der DOI (oder anderen PID, zum Beispiel für Forschungsdaten) längst nicht selbstverständlich. So bleibt die besonders aufwendige intellektuelle Arbeit, die zur Verknüpfung von Wissensbeständen in wissenschaftlichen Veröffentlichungen nötig ist, für Maschinen unlesbar und für Discovery Systeme unnachweisbar.
Nicht nur die freie Verfügbarkeit von Artikeln und Büchern im Open Access verbessert die wissenschaftliche Kommunikation, sondern auch und gerade die dazugehörigen Metadaten müssen offen und in verknüpfter Form vorliegen. Während im Web fast schon monatlich neue Tools zur wissenschaftlichen Recherche entstehen, die etwa Zitationsbeziehungen visuell ansprechend präsentieren, ist die Datengrundlage häufig intransparent. Woher wissen wir, dass wir einen Forschungsstand erfasst haben, wenn wir nicht wissen, auf welchen Ausschnitt der globalen Forschungslandschaft wir überhaupt zugreifen? Können wir nachvollziehen, nach welchen Kriterien unsere Trefferlisten erstellt und geordnet werden?
Bibliotheken kommt daher die Rolle zu, ihre Systeme offen und transparent zu gestalten. Jede wissenschaftliche Recherche muss idealerweise nachvollziehbar und reproduzierbar sein. Gleichzeitig kommt Wissenschaftler:innen die Rolle zu, ihre Veröffentlichungspraxis entsprechend zu gestalten, dass sie für Maschinen lesbarer wird. Keine technische Lösung allein kann die gemeinsame Verantwortung von Wissenschaft und Bibliotheken für den wissenschaftlichen Informationsfluss ersetzen.

 Wissenswerkstatt | SBB-PK CC-BY-NC-SA 3.0
Wissenswerkstatt | SBB-PK CC-BY-NC-SA 3.0 SBB-PK CC BY-NC-SA 3.0 (erstellt: C. Murawski Verzicht auf Namensnennung)
SBB-PK CC BY-NC-SA 3.0 (erstellt: C. Murawski Verzicht auf Namensnennung)
 zu den 54 Kapiteln einer Parodie des Genji-Romans, dem Nise murasaki inaka genji, Farbdruck 1857, Signatur: 37647 ROA | SBB PK") http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN3308100339&PHYSID=PHYS_0008&DMDID=DMDLOG_0001
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN3308100339&PHYSID=PHYS_0008&DMDID=DMDLOG_0001


Ihr Kommentar
An Diskussion beteiligen?Hinterlassen Sie uns einen Kommentar!