Transkribathon ‚Faithful Transcriptions‘ – 58 Tage für 172 Seiten
Von Mai bis Juli 2021 fand der Transkribathon ‚Faithful Transcriptions‘ statt, ein Kooperationsprojekt der Staatsbibliothek zu Berlin und der Universitätsbibliothek Leipzig in Zusammenarbeit mit dem Handschriftenportal-Projekt.
In dem offenen Crowd-Sourcing-Projekt, das sich zum Ziel gesetzt hat, xml-codierte Transkriptionen aus mittelalterlichen Handschriften zu erstellen, haben 107 Teilnehmende in 58 Tagen insgesamt 172 Seiten aus 12 Handschriften transkribiert. Neben zahlreichen individuellen Teilnehmer*innen haben auch Seminargruppen aus den Fächern Germanistik (Prof. Dr. Katharina Philipowski, Dr. Inci Bozkaya, Universität Potsdam) und Kunstgeschichte (Prof. Dr. Kathrin Müller, Humboldt-Universität zu Berlin) bei der Erstellung der Transkriptionen mitgewirkt. Dabei gab es lateinische und deutsche Texte, prachtvoll illuminierte Historienbibeln ebenso wie kleinformatige, eher unscheinbare Gebetbücher und Predigthandschriften, die aber inhaltlich keineswegs weniger interessant waren – überhaupt gab es viel zu entdecken, denn die meisten der transkribierten Texte sind bisher unediert und in der Forschung wenig beachtet worden.
Die intensive Transkriptionsarbeit wurde von einem Rahmenprogramm mit Tutorien sowie wissenschaftlichen Vorträgen begleitet – einige davon können Sie auf dem Youtube-Kanal der Staatsbibliothek nachhören, zum Beispiel den Eröffnungsvortrag von Prof. Dr. Andrea Rapp und Dr. Luise Borek, den Vortrag von Dr. Jakub Šimek zu digitalen Editionen und den Vortrag von Dr. Christian Reul zu OCR-Verfahren.
Die Abschlussveranstaltung
Am 1. Juli 2021 fand die Abschlussveranstaltung zum Transkribathon statt. In der Ergebnispräsentation konnte das Organisationsteam des Transkribathons erste Einblicke in die bisher fertiggestellten Datensets geben.
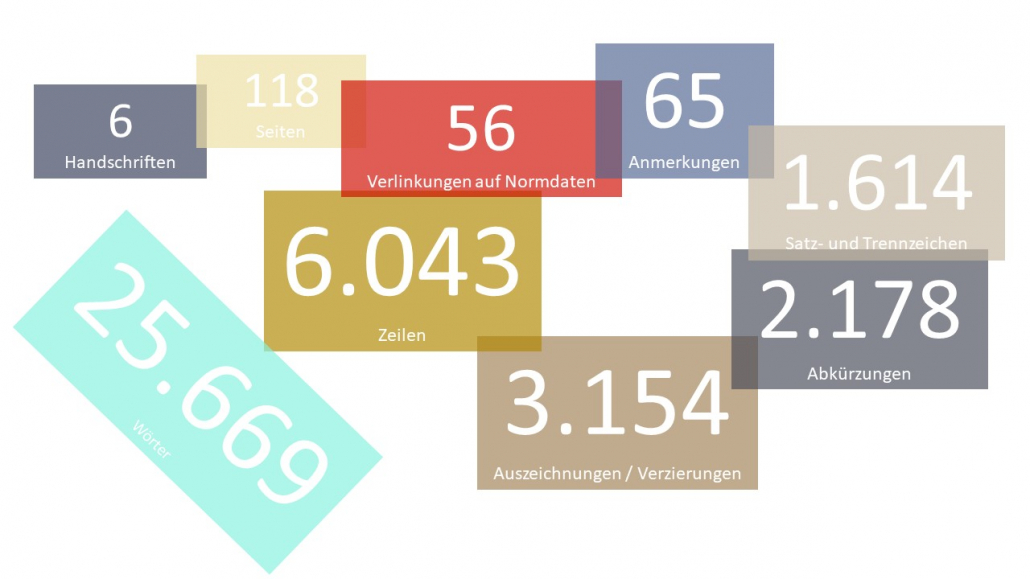
Die fertigen Datensets in Zahlen
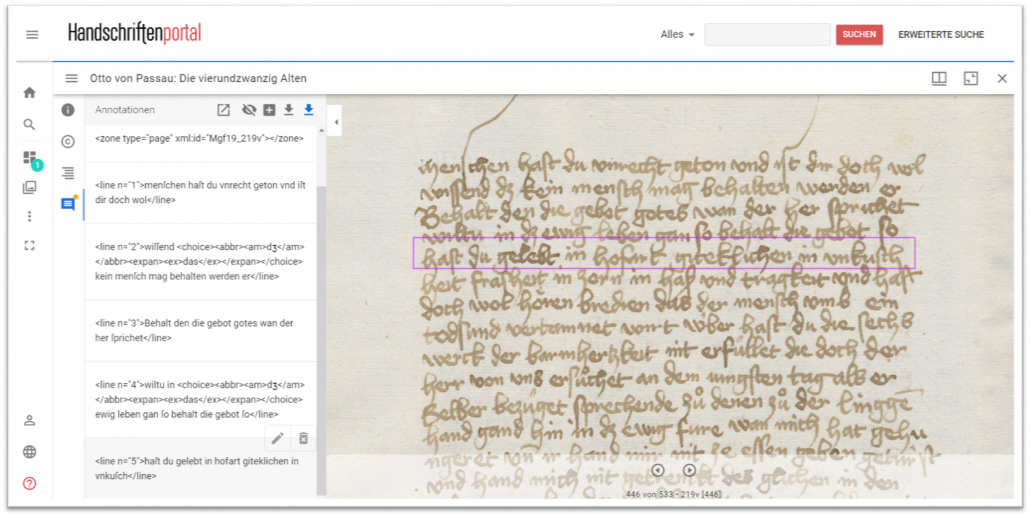
Der Arbeitsablauf beim Transkribathon
Während der Transkriptionsphase fertigten die Teilnehmenden ihre Transkriptionen in dem IIIF-basierten Workspace des Handschriftenportals an, indem sie Annotationen für jede Zeile erstellten und darin den Text in der Auszeichnungssprache XML nach dem Schema „Representation of Primary Sources“ der Text Encoding Initiative (TEI) codierten.
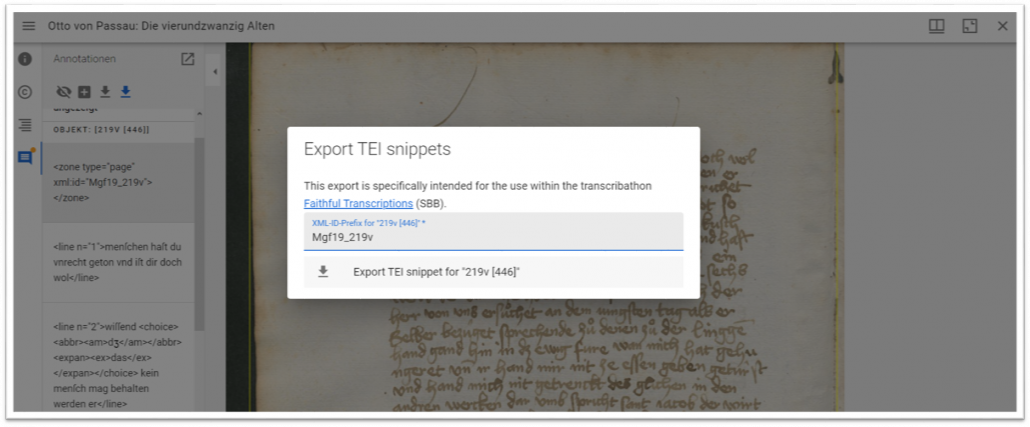
In einem zweiten Schritt wurden die Annotationen mittels einer eigens für den Transkribathon entwickelten Exportfunktion als TEI-Snippet im xml-Format heruntergeladen. Dabei fand eine automatisierte Anreicherung der Daten statt. So wurden z.B. die Koordinaten der jeweiligen Annotationen auf der Digitalsat-Seite mitexportiert und alle Wörter automatisch mit einem <w>-Tag, dem TEI-Element für „Wort“, ausgezeichnet.
Das Organisationsteam des Transkribathons führte dann eine Qualitätskontrolle durch, wobei sowohl die Transkription als auch die xml-Codierung in einem xml-Editor überprüft wurden. Die fertigen Handschriftenseiten stehen nun sowohl als xml-Dateien als auch in einer leichter lesbaren html-Anzeige zur Verfügung.

Publikation und Nachnutzung der Daten
Da wir so viele transkribierte Seiten erhalten haben, war es leider nicht möglich, bis zur Abschlussveranstaltung alle Seiten fertigzustellen. In den nächsten Wochen werden wir uns daher noch weiterhin der Qualitätskontrolle widmen (ausstehend sind noch 54 von 172 Seiten).

Die bereits fertiggestellten Seiten werden laufend im SBB-Lab publiziert. Nach Abschluss der Qualitätskontrolle sollen die Datensets auch als Gesamtpaket auf einem Repositorium publiziert und dadurch für die Forschung nachnutzbar und zitierbar gemacht werden.
Natürlich freuen wir uns sehr, wenn die im Rahmen des Transkribathon erstellten Datensets von der Forschung genutzt werden. Mögliche Nutzungsszenarien liegen sowohl im Bereich der Geisteswissenschaften (digitale Editionen, linguistische Analysen, kunsthistorische Interpretationen) als auch im Bereich der Informatik bzw. der Digital Humanities (Verwendung der Datensets als Ground Truth für Layoutanalyse, Optical Character Recognition bzw. Handwritten Text Recognition).
Berichte von Teilnehmenden
Bei der Ergebnispräsentation wurden aber nicht nur die Datensets vorgestellt, sondern es kamen auch Teilnehmende zu Wort, die von ihren Erfahrungen beim Transkribathon berichteten. Hochschuldidaktische Herausforderungen bei der Teilnahme mit einem Einführungskurs wurden dabei ebenso thematisiert wie Vernetzungsstrategien der individuellen Teilnehmenden untereinander.
Podiumsdiskussion
Den Abschluss der Veranstaltung bildete eine von Dr. Christoph Mackert (Handschriftenzentrum der UB Leipzig) moderierte Podiumsdiskussion, bei der Prof. Dr. Racha Kirakosian (Universität Freiburg), Leander Seige (UB Leipzig) und Dr. Christian Reul (Universität Würzburg) aus ihren jeweiligen Perspektiven – germanistische Mediävistik, digitale Bibliotheksdienste, Informatik – über die Ergebnisse des Transkribathons und deren weitere Verwendung sprachen. In der Gesprächssrunde ging es zunächst um digitale und analoge Editionen mit der Frage nach dem Verhältnis eines einfach gehaltenen ‚Lesetextes‘ zu einer kritischen Edition, die zusätzlich viele Informationen zu Text und Textvarianten enthält – eine Frage, die sich gerade im Hinblick auf die Verwendung einer Edition in der universitären Lehre stellt. Welche Rolle Bibliotheken hier spielen, inwiefern sie Daten bereitstellen und kuratieren und auch die Bildung einer Infrastruktur für offene Daten und offene Software unterstützen, war ein weiterer Themenblock. Im Anschluss an Überlegungen zu Veränderungsprozessen in der Geisteswissenschaft und in der Wissenschaftscommunity waren sich alle Teilnehmer*innen der Podiumsdiskussion einig, dass digitale Editionen und in Crowd-Sourcing-Projekten wie dem Transkribathon entstandene Arbeitsergebnisse in der Forschung noch selbstverständlicher einbezogen werden sollten. Hier ist es nach wie vor eine gemeinsame Aufgabe, mögliche Vorbehalte weiter abzubauen. Dass die Nachnutzung der im Transkribathon erstellten Datensets als Trainingsmaterial für OCR-Verfahren möglich und vielversprechend ist, wurde anhand der OCR4all-Tools praktisch erprobt – wir sind gespannt auf die weitere Nutzung und Auswertung „unserer“ Datensets!
Wir vom Organisationsteam möchten uns an dieser Stelle noch einmal herzlich bei allen Teilnehmenden und Unterstützer*innen bedanken, die zum Gelingen des Transkribathons beigetragen haben, und freuen uns schon auf weitere kooperative Projekte!
![]()
 Public Domain Mark 1.0
Public Domain Mark 1.0

")





 CC0 Staatsbibliothek zu Berlin – Stiftung Preußischer Kulturbesitz | Kollage von Carolin Hahn
CC0 Staatsbibliothek zu Berlin – Stiftung Preußischer Kulturbesitz | Kollage von Carolin Hahn
Ihr Kommentar
An Diskussion beteiligen?Hinterlassen Sie uns einen Kommentar!