
Digitalisierte Sammlungen werden agil: neues Portal und Labor starten in Betaphase
tl;dr: Unsere Digitalisierten Sammlungen wurden umfangreich überarbeitet. In dem neuen Beta-Portal sieht für die NutzerInnen aber fast alles aus wie vorher. Dafür gibt es einen guten Grund.
Die Digitalisierten Sammlungen der Staatsbibliothek gehören zu unseren nachgefragtesten digitalen Diensten. Allein im Monat März verzeichneten wir 30.000 BesucherInnen und über 1/3 Millionen Seitenansichten. Über 100.000 Werke stehen mit mehr als 10 Millionen Seiten in hoher Auflösung (in der Regel 300 dpi oder mehr) zur Verfügung.
Warum überhaupt (noch) eine eigene Präsentationsoberfläche?
In Zeiten knapper und knappster Budges – auch für Bibliotheken – ist diese Frage absolut berechtigt. Mit dem DFG– oder Kitodo-Viewer steht seit Jahren ein einheitliches und funktional gut ausgestattetes Werkzeug zum Lesen von Digitalisaten zur Verfügung, sofern die Metadaten im METS/MODS Format vorliegen. Neue Entwicklungen wie der auf IIIF Technologien basierende Viewer Mirador bieten gute Funktionen im Bereich der synoptischen Bildanalyse. Auf der Nachweisebene folgt die Staatsbibliothek der Devise: keine Digitalisierung und Präsentation eines Werkes, das nicht zuvor im zentralen Katalog (OPAC – StaBiKat nachgewiesen wird. Auch hier kann man also die Sinnfrage einer zusätzlichen Suchoberfläche stellen.
Darum: die Qualität von Bibliotheksdaten sichtbar und nutzbar machen
Schaut man sich jedoch die Struktur der von uns bereit gestellten Daten an, so zeigt sich schnell: gerade an den Schnittstellen von Suchindex zu Trefferliste und von Treffer zu Objektanzeige gehen leicht nutzungsrelevante Informationen verloren. Der OPAC weiß nichts von unseren Strukturdaten (zumeist Inhaltsverzeichnisse, aber beispielsweise auch ausgezeichnete Illustrationen oder Karten), ebenso wenig von unseren OCR-generierten Volltexten. Eine zu einfach gestrickte Trefferliste verschleiert allzu oft, warum eigentlich ein Objekt als Treffer angezeigt wird. Die Feature-Entwicklung von Trefferlisten ist gefühlt vor 10 Jahren stehen geblieben. Bei der Objektpräsentation werden ebenfalls oft die Volltexte versteckt und unsichtbar im Hintergrund gehalten – mit der Konsequenz, das WissenschaftlerInnen keinen Eindruck von der zuweilen ja durchaus problematischen OCR-Qualität gewinnen können.
Ich glaube, dass Bibliotheken gut beraten sind, eigene Kompetenz im Bereich der Suchmaschinentechnologie vorzuhalten und weiter auszubauen. Ebenso im Bereich der graphischen Nutzungsoberflächen. Der Auftrag von Bibliotheken war seit je her nicht nur die Sammlung und Aufbewahrung von Wissen, sondern auch ihre Vermittlung. International regt sich in letzter Zeit Kritik an der Qualität von Google Books – wir können hier nur dann überzeugend mitreden, wenn wir es selbst substantiell besser machen. Niemand kennt die Struktur unserer Daten besser als wir: dieses Potential gilt es zu heben. Und ein Wettbewerb der Ideen ist genau, was wir jetzt brauchen.
Ein neuer Anfang
Die Technologie zur Verwaltung unseres eigenen Suchindex der Digitalisierten Sammlungen der Staatsbibliothek zu Berlin ist in die Jahre gekommen: einzelne Code-Fragmente datieren aus dem Jahr 2004. Es war an der Zeit für eine grundlegende Modernisierung. Was direkt auffällt: durch die neue technische Basis – über die es demnächst hier einen eigenen Beitrag geben wird – wurden teils dramatische Geschwindigkeitsgewinne erzielt. Die folgende Grafik zeigt die durchschnittliche Umblättergeschwindigkeit innerhalb eines Bandes in Bezug gesetzt zum Seitenumfang des Werkes:
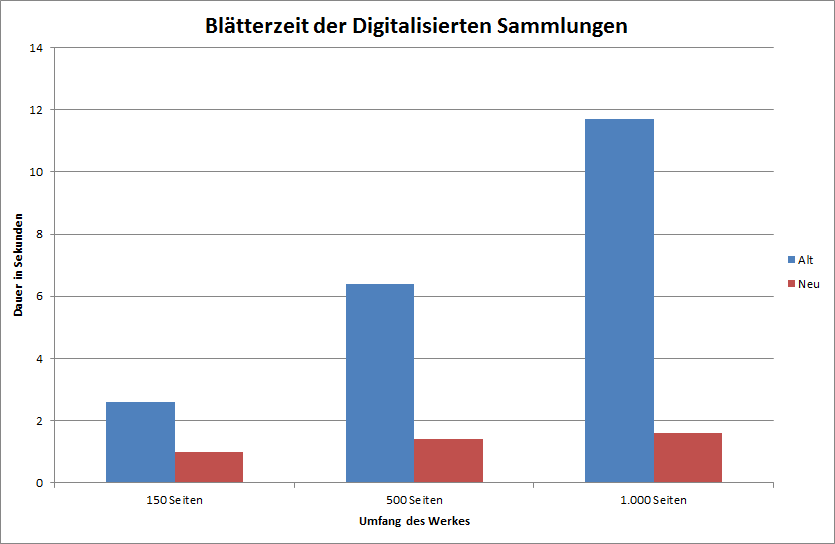
Neben Performance-Steigerungen sind jedoch auf den ersten Blick nur wenige neue Funktionen hinzugekommen. Das hat seinen Grund. Wir haben in unserer „AG Präsentation“ eine gut gefüllte Wunschliste, welche neuen Ansätze wir gern probieren würden – etwa auch und gerade im Hinblick auf die Trefferliste, die wir gern komplett neu denken würden.
Unser Planungsboard – eine open-source-Alternative zu Trello: http://kanboard.net/
Anders als bisher wollen wir jedoch nicht einmal jährlich einen großen Schwung an neuen Features veröffentlichen, sondern lieber einzelne Features zur Diskussion stellen, in viel kürzeren Abständen als bisher. Die neue technische Basis erlaubt uns hier ausgesprochen schlanke Entwicklungsansätze, so dass Experimente und Korrekturen viel schneller umgesetzt werden können. Erfolgreiche Konzepte mögen ihren Weg auch in andere Nachweissysteme finden. Natürlich stehen sämtliche unserer Entwicklungen unter einer open-source-Lizenz, und auch ein Veröffentlichungsmodus dafür ist in Planung – aber das ist genügend Stoff für einen weiteren Beitrag.
Wir stellen uns den zukünftigen Ablauf in etwa so vor:
- Sie testen gründlich unsere neue Beta – http://digital-beta.staatsbibliothek-berlin.de – auf Herz und Nieren, auch und gerade im Vergleich zu der alten Präsentation, die weiterhin verfügbar bleibt.
- Relativ bald würden wir dann die jetzige Beta – einen Erfolg vorausgesetzt – als neue Hauptinstanz umschwenken.
- Das Beta-Portal bleibt jedoch bestehen: hier werden wir in relativ rascher Abfolge jeweils ein neues Feature implementieren, und hier im Blog erläutern und zur öffentlichen Diskussion stellen.
- Bei Gefallen findet es zügig den Weg in die Produktivinstanz, das Beta-Labor steht für das nächste Experiment frei und der Prozess beginnt erneut bei 3.
Unter dieser Adresse https://blog.sbb.berlin/tag/digitalisierte-sammlungen bleiben Sie tagesaktuell auf dem Laufenden, gern auch per RSS-Feed. Ganz entscheidend ist, dass Sie sich einbringen – am liebsten unter diesem Beitrag im Kommentarbereich, möglich sind natürlich auch Kanäle wie E-Mail, Twitter oder Facebook.









 SBB-PK | CC NC-BY-SA 3.0 | erstellt: C. Murawski (Verzicht auf Namensnennung)
SBB-PK | CC NC-BY-SA 3.0 | erstellt: C. Murawski (Verzicht auf Namensnennung)
http://archiv.twoday.net/stories/1022485508/
Liebes SBB-digital-Team, zwei Fragen zur Beta-Version:
1) scheint die Funktion „Durchgehender Volltext“ nicht zu funktionieren, siehe z.B. bei http://resolver.staatsbibliothek-berlin.de/SBB0000C1B400000000
2) Wo finde ich den OCR-Text zum Download? Ist das angedacht, diesen anzubieten? (In welchem Format dann?)
Danke für die Auskünfte! Freundliche Grüße
Christian Thomas
Zu 1) – ja dieses Dokument scheint hier Probleme zu machen, bei diversen anderen funktioniert die durchgehende Volltexansicht. Scheint ein Problem im Datenmodell/Indexer zu sein, wir schauen uns das an.
2) Derzeit geht das nur über Cut&Paste aus der Sicht des durchgehenden Volltextes. Geplant ist, einen Download anzubieten als: txt. TEI, mobi, ePub – eventuell auch noch andere Formate, Wünsche gerne hier hinein. Das soll dann auch über unsere OAI-Schnittstelle ermöglicht werden.
Werte Programmierer_innen,
wenn ich von http://digital.staatsbibliothek-berlin.de/werkansicht/?PPN=PPN619917997&PHYSID=PHYS_0005 auf das Beta-Portal wechsle, wird mir das Bild des Digitalisats nicht angezeigt. Die Dokument-Struktur (Gliederung) scheint vorhanden. Für mich Nutzer ist das Werk selbst aber nicht unerheblich.
Es scheint nicht an einem Ad-Blocker bei mir zu liegen, da dies mit mehreren Browsern unterschiedlicher System nicht funktioniert.
Können Sie bitte die Werbung für das Beta-Portal in der Normalanzeige bei den Werken ausblenden, die im Beta-Portal gar nicht angezeigt werden?
Mit Dank
Marcus Heydecke
Vielen Dank für die Rückmeldung – ich kann das jedoch nicht reproduzieren: der entsprechende Link http://digital-beta.staatsbibliothek-berlin.de/werkansicht?PPN=PPN619917997&PHYSID=PHYS_0005&DMDID=DMDLOG_0001 führt ganz normal auf das richtige Dokument, inklusive der Images, auch auf verschiedenen browsern zu testen…
Liebes Entwickler-Team,
zwei Fragen/Anregungen:
1) die Vollbildanzeige streikt manchmal, etwa in diesem Fall http://digital-beta.staatsbibliothek-berlin.de/werkansicht?PPN=PPN779884310&PHYSID=PHYS_0502&DMDID=DMDLOG_0001
kann aber auch nicht sagen, warum es manchmal klappt und manchmal (häufiger) nicht
2) wäre es möglich beim Wechsel zwischen Einzelbildanzeige und Thumbnailübersicht bei der letzteren genau an die Stelle zu springen, an der man vorher in der Einzelbildanzeige war? So kennen es ja viele aus Google Books und es erleichtert sehr die Durchsicht größerer Dokumente.
Liebe Grüße,
Tobias Kraft
Die Suche nach „Buttenstedt“ ergibt im Portal einen Treffer, bei der Beta-Versionen keinen.
Beste Grüsse, Edi Goetschel
Vielen Dank für den Hinweis! Das Dokument selber ist durchaus auch in der Beta online:
http://digital-beta.staatsbibliothek-berlin.de/werkansicht?PPN=PPN633192929&PHYSID=PHYS_0001&view=overview-toc
Aber im Bereich der Metadaten haben Sie hier einige Unstimmigkeiten aufgedeckt. Die Fehlerbehebung ist im Gange.
Solche Fehlermeldungen sind wirklich sehr, sehr hilfreich für unsere Arbeit.
Liebe KollegInnen, leider funktioniert die Sortierung nach Erscheinungsjahr aufsteigend in den Digitalisierten Sammlungen Beta nicht.
Lieber Herr Stockmann,
Mit trotz Herumsuchens auf der Ihren Seiten nicht klar, unter welchem Umstaenden, eine gesamte HS als eine einzige pdf-Datei („Volltext“) heruntergeladen werden kann.
Wenn ich die verschiedenen Symbole korrekt interpretiere, so ist z.B. fuer diese Amir Hamza HS
http://resolver.staatsbibliothek-berlin.de/SBB0000372A00000000
der Volltext nicht digital zugaenglich.
Es waere u.U. hilfreich, wenn diese grundsaetzliche Frage am Anfang der Einleitung zu Orient Digital beantwortet wuerde.
Mit schoenen Gruessen aus New York
Liebe Frau Riedel,
wir mussten vor einiger Zeit den PDF-Download aus Performancegründen abschalten. Sie können jedoch mit Hilfe des Werkzeug-Kastens einen gesamten Band als .ZIP Archiv laden und haben dann sämtliche Einzelbilder in voller Auflösung:
http://digital.staatsbibliothek-berlin.de/werkansicht/?PPN=PPN638369088&PHYSID=PHYS_0001&view=toolbox
„ZIP-Archiv des ganzen Bandes“.
Oder Sie warten noch eine kurze Zeit: dann werden wir unseren neu gebauten PDF-Download fertig gestellt haben.
Thank you for digitising your Syriac manuscripts and putting them on-line.
I was trying to download some PDFs using the new feature on Sachau Ms 311.
I tried several times with different numbers of pages, (all pages, 300 pages, 100 pages).
Every attempt showed a dialogue box but no progress (always 0%).
After some time, 3 copies of the displayed page were downloaded as PDFs.
Use the latest version of your favourite browser, to generate PDFS. The PDF function works fine with HTML5 compatible browsers only. That was my problem, when I tested it. But it is a nice function.
Als ehemaliger Schriftsetzer bin ich begeistert über diese schönen, alten Liedtexte.
Darf man sich da das eine oder andere Bild kopieren oder ausdrucken?
Mit freundlichen Grüßen
Anton Punz aus Wien
Lieber Herr Punz, selbstverständlich können Sie die Digitalisate nutzen: darum stellen wir sie ja online. Hier finden Sie unsere Nutzungsbedingungen: http://digital.staatsbibliothek-berlin.de/nutzungsbedingungen derzeit vergeben wir die Lizenz cc-by-nc-sa https://creativecommons.org/licenses/by-nc-sa/3.0/de/
UPDATE: wir haben nun einen stark verbesserten PDF-Download frei geschaltet: https://blog.sbb.berlin/relaunch-der-digitalisierten-sammlungen-mit-flexiblem-pdf-download/
Das »verbesserte« erschließt sich mir nicht. Die Digitalen Sammlungen der Staatsbibliothek sind immernoch eine der lahmsten europaweit. Sieht alles fancy aus, hängt aber ständig und brauch für alles unendlich Zeit. Mittlerweile kommt man schneller zum Ziel, wenn man sich die Sourcefiles zieht und selbst ein pdf erstellt. Digital Humanities my ass.
Sehr geehrter Herr Seifert,
hierbei ist denke ich ein Punkt zu berücksichtigen: wir arbeiten bei unseren Digitalisierten Sammlungen nicht mit heruntergerechneten Bildern, sondern nehmen immer die volle Auflösung unserer Scans als Grundlage, ohne Wasserzeichen etc.
Dies ist eine sehr bewusste Entscheidung, gerade aufgrund von Rückmeldungen aus dem Bereich der Digital Humanities.
Dadurch fällen in der Tat auf der NutzerInnenseite die Performance-Anforderungen höher aus als bei Systemen, die alles aus dem Cache ziehen. Aber auch auf nicht sonderlich aktuellen Rechnern – ca 3 Jahre alt aber mit aktuellem Browser (Safari oder Chrome) – komme ich zu diesen Messwerten:
Suche: 1 Sekunde
Aufrufen eines Werkes: 2 Sekunden
Blättern im Werk: 1 Sekunde.
Das finde ich recht passable Zeiten, freue mich aber über den Hinweis eines schnelleren Portals bei _vergleichbarer Imagequalität_.
Werter Herr Stockmann,
ich schreibe zuvorderst aus der Perspektive eines Nutzers. Die technischen Aspekte sind mir in diesem Zusammenhang letztlich egal. Relevant für mich ist die Zeit, die ich tatsächlich brauche, bis ich zu nutzbaren Ergebnissen komme, nicht wie schnell ich diese Ergebnisse letztlich laden kann…
Wenn ich auf die Startseite der Digitalisate beginne, habe ich als Möglichkeiten eine Suche und das Browsen in Kategorien. Gehe ich also über die Suche, sagen wir »Assam«, bekomme ich 624 Einträge. Die Liste als solche kann ich noch weiter eingrenzen über solch »wichtige« Kategorien wie »Historische Drucke (623)« oder »Ostasiatica (621)«. Ich kann auch zwischen »Monografien (221)« und »Band (199)« wählen. Versuche ich eine dieser Teilmengen – z.B. »Mehrbändiges Werk (2)« – mit einem rechtsklick in einem neuen Fenster/Tab zu öffnen, bekomme ich wieder die Ausgangsliste mit 624 Einträgen gestaffelt nach »Relevanz«. Also dasselbe. Was grundsätzlich schon in der Ausgangsliste fehlt, sind simple Eingrenzungsmöglichkeiten wie Jahr, Zeitraum, Sprache, … Die könnte ich natürlich in die Suche über eine Metasprache (zum Teil – Zeitraum fehlt dort genauso) mit einbinden. Aber: man lernt nicht für jede neue Webseite deren explizite Metasprache, nur um die Suche benützen zu können – Digital HUMANITIES beinhaltet ja (auch) das Erschließen und Zugänglichmachen von digitalen Daten für MENSCHEN.
Versuchen wir es über Browsen der Kategorien: »Geschichte/Ethnographie/Geographie« bringt mir 7786 Einträge, geordnet nach »Relevanz«. Was bitte ist »Relevanz«? Ändere ich zu »Erscheinungsjahr« (was als solches nicht in das Menü passt und halb verdeckt wird) werden die Ergebnisse »Absteigend« angezeigt. »Absteigend« mag bei einer Literatursuche in der Hauptbibliothek nützlich sein, um die neueste Literatur zum gegebenen Thema oben präsentiert zu bekommen. Bei Digitalisaten ist sie kontraproduktiv. Hier geht es ja gerade um die alten Werke. Auch hier fehlen sämtliche Möglichkeiten, die Ergebnisse einzugrenzen. Weder Jahr, noch Zeitraum, noch Sprache, noch IRGENDEINE andere Möglichkeit außer den bekannten nutzlosen Kategorien und Strukturtypen. Und auch hier führt das Öffnen einer dieser Kategorie- oder Strukturtypenlinks in einem neuen Fenster/Tab zur Ausgangsliste geordnet nach »Relevanz«.
Wir fassen zusammen: Man kann Suchen (auch das dauert länger als »1 Sekunde«) oder Browsen. Die Ergebnisse einzugrenzen dauert allerdings endlos, da eine Eingrenzung der Ergebnisse unmöglich ist. Passable Zeiten – gewiss – doch ist die Arbeit zähe.
Ich wiederhole: Digital Humanities my ass.
Sehr geehrter Herr Seifert,
wieder direkt ein paar Rückmeldungen:
Da haben Sie einen Fehler entdeckt. Der Drilldown funktioniert, wenn man direkt auf die Facette klickt, nicht jedoch mit einem Rechtsklick in einem neuen Tab. Wir werden das korrigieren.
Zustimmung: wir arbeiten an einer Erweiterung der Facetten sowie einer alternativen „Expertensuche“.
Sie können mit einem Klick auf „Aufsteigend“ die Sortierreihenfolge umstellen, so dass die ältesten Werke oben stehen.
Neues Londoner Kochbuch
Hallo die Damen und Herren,
der PDF-Vorgang – Originale Scanauflösung – „hängt bei 99% !
einen schönen Tag
Hallo,
bei umfangreichen Werken (Ihres hat 600 Seiten) beansprucht der Download sehr stark die Ressourcen Ihres Internetbrowsers. Es gibt zwei einfache Wege: 1) wählen Sie eine geringere Auflösung oder 2) Laden sie den Band in kleineren Abschnitten, beispielsweise zu je 200 Seiten. Sie können auf Ihrem Rechner die einzelnen PDFs dann bei Bedarf wieder zu einem vollständigen vereinen.
Sehr geehrte Damen und Herren,
Stefan Georges Werke sind vielfach zu finden. Um das Programm ‚der Richtung‘
verstehen zu können, sollten aber die 3 ‚Jahrbücher für die geistige Bewegung 1910-12 verfügbar gemacht werden.- Bei der Suche erschien Max Scheler: ‚Krieg und Aufbau‘ Versuche diesen Zufallsfund herunterzuladen waren nicht möglich, bzw. das Verfahren ist so verkorkst-versteckt, dass ich es nicht gefunden habe..
Bei der Gelegenheit möchte ich daran erinnern, dass Stabi’s wirklich vollständige
Ausgabe von Alexander v. Humboldt’s ‚Vue des Cordillères‘ zugänglich gemacht werden sollte. M.Buchen
Selbst wenn man bei der Originalauflösung nur etwa 200 Seiten hat, hängt die Seite ständig NACH dem download (firefox 48 auf osx 10.6.8, verschiedene Bücher) – irgendwelche blöden Scripte hängen sich konstant auf.
Die »geringe« Auflösung ist zum Arbeiten komplett unbrauchbar. Das sind unnötig verbrauchte Ressourcen.
Sehr geehrter Herr Seifert, vielen Dank für die Rückmeldung, über die wie gerade länger diskutieren. Drei Hinweise/Bemerkungen dazu:
1) Der neue PDF-Download wird zu großen Teilen auf dem Rechner unserer Besucher durchgeführt, nicht mehr auf unserem Server. Dies ermöglicht uns, auf in anderen Systemen üblichen Warteschleifen-Mechanismen mit Registrierung etc. zu verzichten. Derzeit machen wir das aber nicht klar genug, wir werden das klarer kommunizieren. Denn:
2) Je älter der Rechner/Browser, desto schwerfälliger verläuft der Download. Ihren Angaben zu OS X entnehme ich, dass der verwendete Rechner ca. 6 Jahre alt ist – das ist für den Download von PDFs in voller Auflösung schon recht grenzwertig. Es bieten sich zwei direkte Lösungen an: entweder teilen sie den Download in mehrere Abschnitte auf, entweder entlang des Inhaltsverzeichnisses (so der Band eines hat) oder direkt im PDF-Download Interface mit der Angabe von Start- und Endseite. So können Sie etwa 100-Seiten Dokumente erstellen die dann auch auf alten Systemen funktionieren sollten. Alternativ haben wir ja den Download so flexibel gestaltet, dass sie nicht nur zwischen „geringe“ Auflösung und „volle Auflösung“ wählen können, sondern auch jeden Wert dazwischen. Hier hilft dann etwas experimentieren.
3) Wir werden das Downloadfenster um eine Hochrechnung erweitern, ob die gerade ausgewählte Anzahl/Qualität mit dem ermittelten Browser/Rechner zuverlässig funktionieren wird. Wenn nicht, wird eine andere Auflösung vorgeschlagen werden.
Hallo Herr Stockmann, das Aufteilen hab ich schon probiert, aber die Ergebnissen sind stark unterschiedlich – mal läuft das bis zum download durch und mal nicht. Die Tendenz ist aber eher in Richtung einer Fehlermeldung, das das »script« nicht weiterläuft. Ich habe keine Ahnung von Ihrem technischen Unterbau, aber java etc hat wohl in den letzten Jahren einiges an Veränderungen durchgemacht. Leider hab ich hier derzeit keinen anderen Arbeitsrechner (außer meinem privaten, auf dem mit 10.9. alles glatt läuft – allerdings auch nur im Firefox und nicht im Safari).
Was mir auch noch aufgefallen ist, sind die verwendeten Schriften, die nicht ansatzweise Diakritika darstellen können, was zu sehr unschönen Brüchen bei den Texten und Bezeichnungen führt. Hier würde ich Ihnen einfach einen anderen Schrifttyp empfehlen. Beim derzeitigen Neuaufbau des hiesigen Archivs haben wir gute Erfahrungen mit der freien PTSans gemacht (es gibt auch Andere). Bis jetzt haben wir noch nichts gefunden, was wir nicht darstellen können – Diakritika und lokale Schriftsysteme wie Devanagari, Tibetisch etc. sind unser täglich Brot…
die an verschiedenen Stellen auftretende Meldung vom System ist:
Warning: Unresponsive script….
Script:
http://digital.staatsbibliothek…685.js?meteor_js_resource=true:48
danach hängt die Seite. wann das passiert kann ich nicht reproduzieren.
»Treffer in x Strukturtypen« führt bei allen Einträgen zur Gesamtsuchmenge – funktioniert also nicht unter älteren Betriebssystemen – ich vermute, auch das liegt wieder am verwendeten scriptsystem…
Sehr geehrter Herr Seifert,
das kann ich nicht reproduzieren. Sie meinen der klassische Drilldown auf die jeweilige Facette funktioniert nicht? Ist dies nur bei dieser Facette der Fall oder auch bei den Kategorien darüber?
wenn Sie mir eine emailadresse schicken, sende ich gerne screenshot zurück.
noch was gefunden: die teilweise vorhandenen Volltexte, die man bei der Darstellung im Browser anzeigen lassen kann, sind in den erstellten pdf nicht enthalten. Suchen in diesen pdf ist damit nicht möglich (zumindest nicht ohne einen zusätzlichen OCR-Durchlauf). Wäre das möglicherweise zu integrieren?
Ja, das steht auf unserer ToDo, ebenso wie der dezidierte Download nur der Volltexte als .ePub, TEI etc. sowie deren Verankerung an der OAI-Schnittstelle.
Guten tag,
Ihre Suchfunktion ist defekt.
Vgl:
14198 Suchergebnisse für Enchiridion Pietatis Rythmicum
Das ist äußerst unwahrscheinlich.
Mfg Joachim Scherf
Hallo,
vielen Dank für den Hinweis – wir haben den Fehler gefunden und behoben.
It really would be appreciated if your site provided an alphabetical list of authors with links to their works. Also, I would love to see the nature/natural history books, and the astronomy books, split into their own categories separate and apart from those books on mathematics.
Is it possible to see a digital reproduction of ms. theol. lat. fol. 336?
Thank you for your kindeness,
Antonio Olivieri
Kann man ds Dokument auch herunterladen?
Meinen Sie die Digitalisate? Aber ja. Wählen Sie ein Werk aus, und gehen dann in der dunkelblauen Leiste im Bereich „Bild“ auf das Schraubenschlüssel-Symbol. Sie haben dann links verschiedene Optionen für den Download, etwa die einzelne Seite als TIFF oder beliebige Bereiche des Dokuments als PDF in frei wählbarer Auflösung.
Hallo,
ich möchte darauf hinweisen, dass im Digitalisat von
Fuisting, Bernhard: Das preußische Einkommensteuergesetz vom 24. Juni 1891 und die …
PPN646877941
im Abschnitt „Einleitung“ die Seiten 48,49 fehlen.
MfG,
Georg Bolz
Vielen Dank, das kann ich bestätigen: wir gehen dem nach.
Sehr geehrter Herr Bolz,
die beiden fehlenden Seiten wurden nachgescannt und sind nun online:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN646877941&PHYSID=PHYS_0070&view=overview-tiles
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN826733077&PHYSID=PHYS_0001&DMDID=DMDLOG_0001
– Evangelisches Andachts-Opffer (S. Franck)
Dieses Digitalisat ist nicht sichtbar. Auch downloaden geht nicht.
This digitalisat is not viewable. If I try to download, also nothing happens.
??
Hallo, wir hatten am Freitag ein technisches Problem, was wir mittlerweile lösen konnten. Das Dokument sollte nun normal funktionieren, bitte probieren Sie es noch einmal.
Schade das die Digitale Bibliothek so langsam ist und es sich darin so schlecht suchen lässt.
Vielen Dank für die Rückmeldung, es würde aber helfen das etwas spezifischer zu haben: die Perfomance haben wir in den letzten Tagen wieder optimieren können, keine Reaktion auf einen beliebigen Klick sollte länger als 2 Sekunden dauern – empfinden Sie dies noch als langsam?
Dann: was genau stört Sie an der Suche?
Dear Sirs, I can’t neither view nor download the document at:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN856415316&PHYSID=PHYS_0005&DMDID=DMDLOG_0001
Signatur: Mus.ms.autogr. Printz, W. K. 1
Can you help me?
Thank you!
We had some technical issues over the weekend, your document should be up and running by now.
in Karlsruhe Catalogue this print is linked as if it were digitalised, but under the title only black pages are displayed.
It has occurred also before with other addresses and prints (don’t remeber now any more, which), if the digitalisation is not available for some reasons, could you put a notification next to it.
However, as a feedback to your site in general: I strongly recommend making whole pdf’s of works downloadable, as e.g. in München libraries: browsing page by page (with average waiting time never less than a minute for a page and often much more) in your Digitalisation collections is really too time-consuming,
with best
Janika Päll
We had some technical issues over the weekend, your document should be up and running by now.
In addition to that, we offer PDF-download for each of your works, for example:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN591194805&PHYSID=PHYS_0003&view=picture-toolbox&DMDID=DMDLOG_0001
(see the tools on the left)
Habe versucht das Buch „Verzeichnis der von den Russen verschleppten ostpreussischen Zivilbevölkerung“ aufzurufen. Leider lud der Scan, trotz eines leistungsstarken PC, nicht.
Hallo, wir hatten am Freitag ein technisches Problem, was wir mittlerweile lösen konnten. Das Dokument sollte nun normal funktionieren, bitte probieren Sie es noch einmal:
http://resolver.staatsbibliothek-berlin.de/SBB00007D0D00000000
Sehr geehrte Damen und Herren,
der Autor des Werkes heißt Abū l-Faḍl Muḥammad b. ʿUmar b. Ḫālid, genannt Ǧamāl al-Qaršī, vgl. Peter Jackson, Art. Djamāl Ḳarshī, in: EI2, Suppl.-Bd., Leiden 2004, S. 240.
Betr. Ms. http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN689123868&PHYSID=PHYS_0001&DMDID=DMDLOG_0001&view=overview-info.
Mit besten Grüßen
Undine Ott
Sehr geehrte Frau Ott,
danke für den Hinweis, wir werden den Datensatz bei nächster Gelegenheit korrigieren.
Mit freundlichen Grüßen
C. Rauch
Vielen Dank für den Hinweis: das Werk wurde nun korrigiert.
Guten Tag,
die von Ihnen angeboten Möglichkeit, Bücher digitalisert herunterzuladen, funktioniert noch immer nicht fehlerfrei.
Das Herunterladen des Buchs http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN770842577&PHYSID=PHYS_0049&DMDID=DMDLOG_0001
bricht mit Chrome und InterExplorer ab, sogar, wenn man nur die Hälfte laden will.
Ich empfehle Ihnen dringend, Ihre Software-Abteilung oder Ihren Dienstleister zu besserer Leistung anzuspornen.
Immerhin sind die Probleme in Ihrem Haus nicht neu, sie währen seit Jahren.
Ihr Joachim Scherf
Gibt es wirklich keine Moeglicheit, Ihre Digitaliate zu drucken?
Nigel Palmer
Sehr geehrter Herr Palmer,
natürlich können Sie unsere Digitalisate auch drucken. Ich würde hier drei verschiedene Wege vorschlagen:
1) Schnelldruck einer einzelnen Seite
Steuern Sie die gewünschte Seite in den Digitalisierten Sammlungen an, und wählen Sie dann in der Menüleiste oben den Werkzeugkasten an. Sie kommen dann beispielsweise auf so eine Seite: http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN769496156&PHYSID=PHYS_0067&view=picture-toolbox und finden dort links die Option „JPG-Datei der Seite 1200px“. Wenn Sie das anwählen, wird die Seite direkt im Browser in einer mittleren Auflösung ohne störenden Rahmen gezeigt und kann über die Browser-Druckfunktion ausgedruckt werden.
2) Wenn sie für eine einzelne Seite perfekte QUalität benötigen, wählen Sie in der selben Seitenleiste „TIFF-Datei der angezeigten Seite“. Damit wird das Original – natürlich ohne Wasserzeichen – in optimaler Qualität auf Ihrem Rechner gespeichert, von wo aus Sie es nach Belieben verwenden oder drucken können.
3) Für den Druck mehrerer Seiten oder gar eines kompletten Bandes Wählen Sie hingenen in der Seitenleiste „PDF des ganzen Bandes“ aus und wählen im Nachfolgenden Dialog Seitenumfang und Qualität. Das PDF können Sie entweder auf Ihrem Rechner weiter verarbeiten, oder aber auch drucken.
Guten Tag,
das alte Problem:
Diesmal Abbruch beim Herunterladen des Werks
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN664340490&PHYSID=PHYS_0007&DMDID=
Warum bringen Sie die Funktionen nicht endlich in Ordnung?
Ihr Joachim Scherf
Sehr geehrter Herr Scherf,
vielen Dank für Ihre Rückmeldung. Wir verbessern ständig die Stabilität des PDF-Dienstes, aber Sie müssen bedenken: was wir hier an Funktion anbieten, ist innerhalb der Welt der internationalen Digitalisierten Sammlungen eher ungewöhnlich: um unterschiedlichsten Forschungsinteressen entsprechen zu können, bieten wir maximale Flexibilität beim PDF-Download (den es an sich anderswo schon eher selten gibt). Und anders als 99% der anderen Bibliotheken „verstecken“ wir auch nicht unsere Originalqualität, sondern liefern sie direkt und ohne Nachfragen einfach aus. Hierbei haben wir es jedoch mit enormen Datenmengen im Petabyte-Bereich zu tun, und das ist auch für ein größeres Rechenzentrum wie wir es betreuen eine Herausforderung.
Ein Beispiel: die nahe liegende Forderung „dann berechnen Sie die PDFs doch einfach alle vor“ würde bei unseren 212.000 Werken dauern: drei Monate.
Wir versuchen also einen Ausgleich zu schaffen zwischen Stabilität (Ihr Anliegen) und Flexibilität (die Anliegen vieler Anderer). Es tut mir leid, wenn dieser Ausgleich derzeit nicht zu Ihrer Zufriedenheit ausfällt.
Guten Tag,
das Laden des genannten Werks bricht noch immer ab. Weder an der Schnelligkeit noch an der Zuverlässigkeit hat sich etwas geändert (beide Komponenten sind nach wie vor miserabel). Ich bin von Ihrer Dienstleistung sehr enttäuscht, zumal die Probleme seit Jahren bestehen.
MfG J. Scherf
Sehr geehrter Herr Scherf,
das tut mir Leid – wird sich aber, wie ich oben schrieb, kurzfristig nicht ändern lassen. Der PDF-Download ist eben nur ein Features von vielen, an denen wir arbeiten.
Bis dahin ist – wie bereits beschrieben – der beste Weg für Sie: Laden sie PDFs in kleineren Portionen herunter, beim angegebenen Werk beispielsweise zu je 200 Seiten – das sollte funktionieren.
Hallo,
gerade eben Ms. Danzig 4023a http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN848572777&PHYSID=PHYS_0001 heruntergeladen.
Die Reihenfolge der Scanns ist grob durcheinander, bitte richtigstellen.
Ansonsten: Super! Kleinigkeit: Feedback durch Formular ist muehsam, bitte (auch) Mailadresse angeben (da haette ich zb. die richtiggestellte Reihenfolge mitsenden koennen).
Hallo und das Gleiche nocheinmal:
„Tänze aus Vorpommern und Rügen“, SBB Mus.ms. 38251
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN865212104&PHYSID=PHYS_0001
Auch hier ist die Reihenfolge der Scanns ist grob durcheinander, bitte richtigstellen.
Irgendwie hab ich jetzt 2 Scanns heruntergeladen und bei beide ist die Reihenfolge falsch. Kann es sein, dass z. B. das Tool das die PDFs erstellt Murks macht?
MfG Simon Wascher
Sehr geehrter Herr Wascher,
wir haben uns beide genannten Vorgänge (MS. Danzig 4023a und Mus.ms. 38251) heute sowohl im Viewer als auch im pdf-Download angesehen und konnten keine Abweichungen bei der Reihenfolge der Seiten feststellen.
Zu beachten ist allerdings, dass sich der Download von Teilen eines Werkes an den Imagenummern und nicht an den Seitenzahlen des Originals orientiert – hier ist die Ausschrift im Dialogfeld momentan nicht ganz exakt.
Mit freundlichen Grüßen
Roland Schmidt-Hensel
Bin gerade bei Recherchen in den digitalisierten Sammlungen auf die PDF-Konvertierung gestoßen: Super Service!
Vielen Dank!!!
Hello, I’ve tried to download the pdf of the entire document of Beethoven, Symphony N° 9, but there’s a technical problem at the end of the process. It couldn’t go through. Could you please find out what the problem is? Thanks for your help.
Liebe Staatsbibliothek,
vielen Dank für die (kostenlose) Bereitstellung Ihrer digitalisierten Sammlungen! Leider nur funktioniert das Herunterladen eines ganzen Bandes im pdf-Format nur sehr schlecht und bricht in der Regel ab oder es gibt sonstige technische Probleme bei der Erstellung des Dokuments.
Gibt es einen Grund dafür, dass Sie nicht auch (wie Google Books und einige andere Anbieter) bereits erstellte pdf-Dokumente zum Download bereitstellen? Das unten (unter „Webseite“) verlinkte Dokument habe ich bereits fünf oder sechs Mal zu generieren versucht, bislang jedoch ohne Erfolg.
Vielen Dank und beste Grüße
Vielen Dank für die Rückmeldung. Wir arbeiten an einem Verfahren, das auch den verlässlichen Download ganzer Bände als hochauflösendes PDF erlaubt. Bis dahin können wir nur darauf verweisen, dass der Download einzelner, kleinerer Kapitel oder die Auswahl einer niedrigeren Auflösung gut funktioniert.
Noch eine kurze Antwort zur Frage „warum nicht alle vorberechnen“: bei unserem derzeitigen Bestand von über 120.000 Dokumenten würde da ca. 3 Monate dauern und wäre einigermaßen fehleranfällig, wie gesagt arbeiten wir an einer eleganteren Lösung.
Liebe StaBi, lieber Ralf Stockmann,
der Aufruf von http://digital.staatsbibliothek-berlin.de/werkansicht/?PPN=PPN779884310 (Humboldts Amerikanisches Reisetagebuch VII bb u. c) führt im Moment zu einer Seite, die – so scheint es – von woanders in die Darstellung reingerutscht ist. Es handelt sich um das Titelblatt einer Schrift zu Ehren des sächsischen Herzogs Ernst Friedrich III. (wenn ich das richtig sehe), die aber mit Humboldts Tagebuch nichts zu tun hat. Ein Osterei?
Dazu fiel mir auf, dass der Ladevorgang für die Anzeige weiterer Seiten im Moment sehr stark verlangsamt ist.
Da die Tagebuch-Digitalisate intensiv von der Humboldt-Forschung verwendet werden (soweit ich das überblicken kann), wäre es toll, wenn Sie die beschriebenen Probleme bald angehen könnten.
Vielen Dank und beste Grüße,
Tobias Kraft
entschuldigung, ich meinte „Amerikanisches Reisetagebuch VII a u. b“
Vielen Dank für den Hinweis: der Fehler wurde behoben.
i can not find regerings almanak voor nederlandsch-indie 1935,can you help me how can find the book
Sehr geehrte Damen und Herren
Unter http://resolver.staatsbibliothek-berlin.de/SBB0001511900000000
haben Sie die Bibel mit den Holzschnitten von Tobias Stimmer digitalisiert:
NOVVM TESTAMENTVM IESV CHRISTI, FILII DEI, Primò quidem studio & industria D.Erasmi … Straßburg: Theodosius Rihel, 1560.
Mich würde interessieren, wie Sie auf das Datum kommen. Das Titelblatt gibt keine Datumsangabe, und der Bearbeiter im New Hollstein ## 1165-1283, Paul Tanner, schreibt: „s.a.“
(Das wäre deshalb von Belang, weil Stimmer 1576 die Bilder zu den „Neuen künstlichen Figuren“ beigesteuert hat.)
Freundliche Grüße: P.Michel
Der Kanarienvogel : Zucht und Pflege desselben sowie anderer … , 1885
Is NOT loading.
Thank you very much for the hint. This work has been published too early: it’s not digitized yet. Please visit us again in a couple of days.
…and now its online:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN88166426X&PHYSID=PHYS_0005&view=overview-tiles
Liebes Team der Staatsbibliothek,
ich bin beeindruckt und fasziniert von Ihrem Digitalisierungsprogramm. Leider habe auch ich wie viele andere Nutzer vor mir, Probleme mit dem Laden der Daten. Konkret habe ich versucht, zwei Bilderbücher von Tom Seidmann-Freud, „Das Buch der erfüllten Wünsche“ und „Das neue Bilderbuch“ zu laden. Da ich die Seiten gern verlinken würde, um sie Studierenden zugänglich zu machen, wäre ich sehr dankbar für einen Hinweis, wie ein zuverlässiger Zugriff darauf möglich ist.
Mit freundlichen Grüßen
Dr. Stephanie Heimgartner
Hallo,
vielen dank für die Rückmeldung. Wir arbeiten beständig daran, unseren Dienst noch robuster zu gestalten – innerhalb der letzten 5 Wochen hat sich die Nutzung fast verdoppelt, was zu Engpässen führte. Wir haben mittlerweile unsere Serverkapazitäten nachgezogen: die von Ihnen erwähnten Werke sind nun eigentlich gut erreichbar.
Just posted to Project Gutenberg: History of Gujarat, by James McNabb Campbell, transcribed from the scans you provided on your site. (Thanks!)
Link: https://www.gutenberg.org/ebooks/54652
GitHub for TEI master file: https://github.com/GutenbergSource/54652-Campbell-History-of-Gujarat
For some reason, the G minor suite of Le Roux’s is not longer available, which is a shame since I need to check it before sending my paper to the publisher in the morning. Is there a PDF file available of this, or could you perhaps fix your website?
Hi, If you refer to this one:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN773128603&PHYSID=PHYS_0503&view=overview-tiles
it should be up and running?
Ihre Downloadroutine für PDFs ist eine einzige Katastrophe. Nicht eine einzige ist mir bisher geglückt. Nicht einmal dann, wenn ich nur kleine Teile eines Buches downloaden wollte. Vielleicht kontaktieren Sie die Bayerische Staatsbibliothek. Da klappen die Downloads immer – auch bei größeren Büchern.
Sehr geehrter Herr Boer,
vielen Dank für diese kritische Rückmeldung. Können Sie bitte ein Werk nennen, das hier solche Probleme bereitet? Ein weiterer Einflussfaktor kann Ihr verwendeter Browser sein: die PDFs werden erst „auf Zuruf“ hin berechnet, und zwar lokal in ihrem Browserprogramm. Ein veralteter Browser sowie zu wenig Hauptspeicher (<8 MB Ram) kann hier zu Problemen führen.
Alternativ zum PDF-Download steht ihnen auch immer die Möglichkeit bereit, alle Seiten in voller Auflösung ohne Berechnung als .zip Archiv herunter zu laden – bei Bedarf können Sie dann ein PDF daraus selbst erstellen.
Guten Tag,
wie fast immer: nach 1/2 Stunde Ladezeit: Abbruch des Ladevorgangs
M. G. andächtiger Seelen, vollständiges Gesangbuch, darinnen der Kern … : Mit einem Anhange von Morgen- Abend- und … , 1798 (http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN86987313X&PHYSID=PHYS_1288&DMDID=DMDLOG_0080).
Ihre Dienstleistung, aus Steuermitteln finanziert, ist nicht nur katastrophal, sondern inzwischen eine Unverschämtheit, da Sie nichts unternehmen, um den Missstand zu beseitigen. In jedem Unternehmen hätten die Verantwortlichen längst die Kündigung erhalten, und das zu Recht.
J. Scherf
Sehr geehrter Herr Scherf,
Ihr Hinweis betrifft vermutlich wiederum den PDF-Download. Wie Herr Stockmann Ihnen bereits beschrieben hat, können wir Ihnen diesen derzeit nur in dieser Form anbieten, d.h. die PDF-Generierung erfolgt direkt in Ihrem Browser und ist von der Leistungsfähigkeit Ihres Browsers abhängig. Alternativ können Sie Werke in Teilen oder durch Auswahl der Funktion „ZIP-Archiv des ganzen Bandes“ die Bilddateien des gesamten Werkes herunterladen und bei Bedarf ein PDF daraus erstellen. Bei umfangreichen Dokumenten (wie in dem von Ihnen genannten Fall mit nahezu 1500 Seiten) empfehlen wir den Download einzelner Abschnitte, bei Textdokumenten könnte eventuell auch eine geringere Pixelzahl genügen.
Eine Überarbeitung des PDF-Downloads ist zukünftig vorgesehen.
Sehr geehrte Damen und Herrn,
beim Stöbern bin ich über folgende Seite gestossen:
Irgendwas passt da nicht. Laut dem Titel der Seite ist es das Adressbuch von 1874. Die im Digitalisat vorkommende Zahl ist 1786. Auch der Inhalt scheint mir kein Adressbuch zu sein.
Mit freundlichen Grüßen,
Gerhard Stoll
Sehr geehrter Herr Stoll,
schicken Sie uns bitte noch den Link zu Ihrer Fehlermeldung, er fehlt in Ihrem Kommentar.
Mit freundlichen Grüßen,
Gudrun Nelson-Busch
Sehr geehrte Fra Nelson-Busch,
es geht um das Buch „Adreßbuch der Haupt- und Residenzstadt Königsberg i. Pr. und der … , 1874“
Link:
oder
Mit freudlichen Grüßen, Gerhard Stoll
Warum werden die Links verschluckt?
http://resolver.staatsbibliothek-berlin.de/SBB0001E1B6000D0000
Neuer Versuch ohn das dieser mit eingeklammert ist.
So aller guten Dinge sind drei.
http://resolver.staatsbibliothek-berlin.de/SBB0001E1B600030000
Sehr geehrter Herr Stoll,
vielen Dank für Ihre Fehlermeldung. Hier sind offenbar die falschen Bilder angehangen worden. Wir haben die Anfertigung der korrekten Digitalisate des
Adreßbuch der Haupt- und Residenzstadt Königsberg i. Pr. und der Vororte; Jahr 1874 veranlasst.
Sollten Ihnen weitere Unstimmigkeiten auffallen, können Sie uns diese immer gern melden.
Mit freundlichen Grüßen
M. Federbusch
FYI:
Bei meiner Suche nach ar-Rūmī al-Maulawī
funktionieren einige Digitalisate nicht,
z.B.
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN719886856&PHYSID=PHYS_0006
Vielen Dank für Ihren Hinweis. Das genannte Digitalisat konnte ich soeben problemlos aufrufen. Versuchen Sie es bitte erneut? Und senden Sie uns gern Links zu nicht aufrufbaren Digitalisaten, damit wir Fehler ggf. schnell beheben können.
Hi there,
The following URLs do not seem to load any images?
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN856141240&PHYSID=PHYS_0001
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN856141429&PHYSID=PHYS_0001
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN857347373&PHYSID=PHYS_0001
Thanks!
Hi,
thanks for the advice. We try to fix it as soon as possible.
The problem for these objects was fixed and the images load properly. Sorry for the inconvenience.
Hallo! Bei der Digitalisierung dieses Notenbandes ist 2014 sicher ein Fehler unterlaufen. Von dem angegebenen Satz „Capriccio“ des Gesamtwerkes ist leider nur die Titelseite und eine Leerseite gescannt worden.
http://resolver.staatsbibliothek-berlin.de/SBB0001072500000000
Vielen Dank für Ihren Hinweis. Wir versuchen, die im Digitalisat fehlenden Seiten rasch zu ergänzen.
Die fehlenden Seiten des „Capriccio“ stehen nun auch digital zur Verfügung: http://resolver.staatsbibliothek-berlin.de/SBB0001072500000000 . Danke für Ihren aufmerksamen Hinweis und Ihre Geduld.
Hi,
Katalog der Diez’schen Handschriftensammlung – Verzeichnis der morgenländischen und abendländischen Handschriften in … : Ms. Cat. A 478b , 1790 – unfortunately does not seem to load any images ( http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN731531906&PHYSID=PHYS_0001&DMDID=) Only black pages are displayed perhaps due to some technical issue. Is there a pdf file available for the entire catalogue in question? Thanks in advance for your help,
Hi, please try again – it should be up and running by now. In addition to that, you may get the PDF here:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN731531906&PHYSID=PHYS_0001&DMDID=&view=picture-toolbox
Best, Ralf
Lieber Christian etal,
gerade wollte ich mir Eure En no Gyoja Rolle anschauen, da ich ein Vergleichsrolle in der New York Public Library morgen oder nächste Woche (habe 2 Termine) anschauen darf. Jedes Mal, wenn ich auf die angezeigte Rolle klickte, kam dieses error Bild mit den lustigen, verwurstelten Fäden oder was das sein soll. Hab ich da was falsch gemacht? Oder kann man den Fehler vielleicht beheben und wenns geht schnell? Ich würde so gerne die Visuals als Vergleich dabei haben, wenn ich in der NYPL bin. Tausend Dank für ne rasche Antwort. Herzliche Grüße, melanie
Sorry, habe vergessen, die URL von der En no gyoza Rolle mit reinzukopieren:
http://digital.staatsbibliothek-berlin.de/suche?category%5B0%5D=Japonica&category%5B1%5D=Ostasiatische%20Handschriften&queryString=えんの行者&fulltext=&junction=¤t_page=1&results_on_page=20&sort_on=relevance&sort_direction=desc
Hallo, aufgrund eines technischen Fehlers wird die erste Seite (Buchrücken) nicht angezeigt. Bis wir das behoben haben, können Sie jedoch den Rest des Werkes schon betrachten:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN3308101238&PHYSID=PHYS_0015&DMDID=&view=overview-tiles
Für Rollen empfehlen wir dabei unseren Vollbild-Modus (wird auf einer Einzelseite oben rechts aktiviert)
Viele Grüße
Ralf Stockmann
Guten Tag,
beim download des ZIP-Archivs zur HS Ms. germ. fol. 244 wird (unabhängig vom verwendeten Browser) ein fehlerhaftes ZIP-Archiv ausgeliefert, dass sich mit keinem gängigen Tool entpacken lässt.
Könnten Sie das Problem bitte beheben?
LG
Helmut Klug
Sehr geehrter Herr Klug,
vielen Dank für Ihr Anfrage. Das .ZIP Archiv funktioniert hier bei mir (Google Chrome, Windows 10, 16GB Ram) – allerdings ist es dank über 600 Seiten und hoher Scanauflösung wuchtige 4.1 Gigabyte groß. Da können beim Download etliche Komponenten aus dem Tritt kommen – Browserspeicher, Browser-Timeouts, Begrenzungen des lokalen Dateisystems etc.
Der sicherste Weg ist nun, auf den PDF-Download auszuweichen, dort die Bildauflösung auf das gewünschte Maß zu setzen (vielleicht wird nicht die volle Auflösung benötigt?) und dann in Abschnitten (etwa: jeweils 100 Seiten) herunterzuladen.
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN785884734&PHYSID=PHYS_0001&view=picture-toolbox
Aus dem PDF kann man dann wiederum die Einzelbilder extrahieren, wenn man nicht gleich direkt mit dem PDF arbeiten möchte.
Viele Grüße
Ralf Stockmann
To whom it may concern,
There is a missing link on the following page:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN822195739&PHYSID=PHYS_0008&DMDID=DMDLOG_0001
At the moment, it is not possible download the manuscript D-B Mus.ms. Bach P 1048, the score of cantata BWV 159 as only the „Farbinformation“ is listed in the downloads.
Dear Mr. Lanthier,
you may use the links on this page to get the (PDF) download of the document:
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN822195739&PHYSID=PHYS_0001&DMDID=DMDLOG_0001&view=picture-toolbox
Best,
Ralf Stockmann
When I download a complete document as PDF, it is not searchable, for instance I downloaded, http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN789526255&PHYSID=PHYS_0001&DMDID=DMDLOG_0001&view=picture-toolbox
but cannot search it. Am I doing something wrong, or is it because I am working with a MAC ? I tried Preview and Adobe Acrobat reader. Thanks for your advice .
Dear Mr. Wessel,
as of now, we do not offer fulltext PDFs – just the images. Binding our OCR-fulltext to a hidden layer in the PDF is on our roadmap, though.
Best,
Ralf
Ah, schade… Aber danke für Ihre Antwort.
Thanks,
Jan
Warum sie erlauben NICHT download lso BSB München und andere? Sie Größe? Fuj!
Hallo, natürlich erlauben wir einen Download unserer Werke in bester Qualität und ohne Wasserzeichen als JPG, TIFF, .ZIP oder PDF. In unserer Beta-Version haben wir den Download-Bereich noch expliziter ausgewiesen, etwa:
https://digital-beta.staatsbibliothek-berlin.de/werkansicht?PPN=PPN666097623&PHYSID=PHYS_0125&DMDID=&view=picture-download
Viele Grüße
Ralf Stockmann
Bei der Suche in den digitalisierten Sammlungen werden Suchwörter automatisch mit ODER verknüpft, während die Benutzer wohl normalerweise eine Verknüfung mit UND erwarten, um die Suchergebnisse einschränken zu können. Ebenso ist es unbefriedigend, dass automatisch im Volltext gesucht wird, ohne dass eine Einschränkung auf Titelwörter möglich ist. Etwas flexiblere Suchmöglichkeiten wären eine große Hilfe!
Jede dieser Anmerkungen unterstütze ich mit Nachdruck!
FYI – Beim Stöbern entdeckte ich, dass sich
Politi, Raffaello: Illustrazione Ad Un Vaso Fittile Rappresentante Cassandra E Ajace … , 1828
http://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN736428925&PHYSID=PHYS_0021&DMDID=
in der Beta-Version nicht öffnen lässt. Liegt es an meinem Rechner oder ist da was falsch?
Danke für das tolle Angebot!
Die Seiten sind zwar optisch recht schön, brauchen aber lange zum Laden. Außerdem funktioniert die Download-Funktion des ganzen Werkes oder größerer Teile nicht: Der Download bricht immer mit Fehlermeldung ab. Es werden maximal ca. 40 Seiten zugelassen, aber nach 2 Downloads geht auch das nicht mehr.
Beim Ordnen der Ergebnisse nach Erscheinungsjahr ist die Grundeinstellung immernoch »absteigend«, was für die Suche nach ALTEN Quellen etwas kontraproduktiv ist. Viel schlimmer ist der derzeitige Zustand: selbst wenn ich von Hand auf »aufsteigend« umstelle, stellt irgendein fancy Script das Ganze nach etwa 10 Sekunden wieder auf »absteigend«. Wer hat da wieder feuchte Benutzungsträume gehabt? Es ist erschreckend, das nach einem derart langen Entwicklungszeitraum immernoch ein derartiges Chaos bei der Benutzungsoberfläche herrscht.
> Beim Ordnen der Ergebnisse nach Erscheinungsjahr ist die Grundeinstellung immernoch »absteigend«, was für die Suche nach ALTEN Quellen etwas kontraproduktiv ist. Viel schlimmer ist der derzeitige Zustand: selbst wenn ich von Hand auf »aufsteigend« umstelle, stellt irgendein fancy Script das Ganze nach etwa 10 Sekunden wieder auf »absteigend«
Sehr geehrter Herr Seifert, „absteigend“ ist in bibliothekarischen System eigentlich überall der Standard – neueste Werke immer zuerst. Man kann darüber diskutieren, ob dies beim Altbestand so auch Sinn macht, aber mit einem Klick lässt sich das ja umstellen auf „aufsteigend“.
Nicht reproduzieren kann ich allerdings Ihr Problem, dass sich das nach ca. 10 Sekunden automagisch wieder zurück stellt – weder unter Chrome, noch Firefox oder Edge. Mit was für einem Betriebssystem/Browser sind die unterwegs, und passiert das auch wenn Sie von Ihrem Standardbrowser wechseln?
Werter Herr Stockmann, gestern hatte ich tatsächlich reproduzierbar das Problem des Zurückstellens. Jetzt scheint es wieder zu gehen. Die Darstellung der Ordnungskategorie wird allerdings immernoch – wie schon 2015 – bei Begriffen länger als »Relevanz« rechts abgeschnitten. »Aufsteigend« und »Absteigend« drängelt auch noch. Aber das ist nur ein optisches Problem. Was ich immernoch vermisse ist eine erweiterte Suche, die Jahre etc. einschränken kann. MfG Jan Seifert
Ich benutze immernoch den Randgruppenbrowser Safari, derzeit in Version 11.1.1. 😉
Und gerade passiert es wieder – Aufsteigend wird zu Absteigend. Nach wenigen Sekunden.
Diesmal ist es nach drei Versuchen bei Aufsteigend verblieben… ich verstehs nicht.
»Sehr geehrter Herr Seifert, “absteigend” ist in bibliothekarischen System eigentlich überall der Standard – neueste Werke immer zuerst. Man kann darüber diskutieren, ob dies beim Altbestand so auch Sinn macht, aber mit einem Klick lässt sich das ja umstellen auf “aufsteigend”.«
jetzt sitz ich auch schon wieder seit MINUTEN vor dem Rechner und warte, dass das script 276 Ergebnisse von »absteigend« nach »aufsteigend« umsortiert. Rechnerauslastung zwischen 1 und 2%, Speicher ausreichend etc etc. Stille. Nichts. Ich sollte wohl aufgeben.
Um auch mal was Positives beizutragen: Die Integration der (Download-) Tools ist viel besser als am Anfang. Das Herunterladen auch großer Werke in Originalauflösung klappt mittlerweile (beim mir) problemlos. Rechnerauslastung und Speichernutzung ist gering. Danke dafür!
http://resolver.staatsbibliothek-berlin.de/SBB000076D200080000 hat keine Inhaltsseiten, nur einen Einband
Lieber Herr Seifert, danke für das Auffinden des Fehlers. Bei diesem Werk sind die Daten in den zugrundeliegenden XML-Dateien fehlerhaft oder die Indizierung für diesen speziellen Fall. Wir haben es als Ticket aufgenommen und werden den Bug schnellstmöglich beheben.
Lieber Herr Seifert, es war ein Fehler in der Datenhaltung, der seit eben korrigiert ist. Alle Seiten werden jetzt in der Navigation angezeigt und können direkt angewählt werden. Danke für das Auffinden und den Hinweis an uns.
Vielen Dank für die schnelle Abhilfe.
Kann es sein, dass derzeit der Resolver nicht korrekt funktioiniert? Unter http://resolver.staatsbibliothek-berlin.de/SBB000008DB00000000 gibt es:
Fehler: Verbindung unterbrochen
Die Verbindung zum Server wurde zurückgesetzt, während die Seite geladen wurde.
Unter https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN612521494 ist der Titel aber zu finden …
Liebe Frau Ellis,
besten Dank für den Fehlerhinweis. Es gab bei dem Resolver zu diesem Zeitpunkt eine temporäre Störung, die am Freitag, den 16.11.2018 behoben wurde.
besten Gruß,
Marco Scheidhuber
Sehr geehrte Damen und Herren,
ich suche den zweiten Band von Nicolas Vallet „Apollinis süsse Leyr“. Sie haben Online den Band für ein Bass Instrument, es fehlt den Band der für ein hoheres Instrument ist, der sollte Viol oder etwas ähnliches heißt. Ich würde es Ihnen sehr danken! Herzliche Grüße aus Bremen, Sergio Coto
Hallo,
ich würde sehr gerne die IIIF-Schnittstelle in einer eigenen App nutzen – gibt es dazu eine entsprechende Dokumentation? Aus dem Wühlen im Quelltext bin ich leider noch nicht ganz schlau geworden, ob und wie persistente Verweise zu manifest-Dateien existent sind.
Gefunden habe ich die info.json-Dateien für einzelne Bilder (z.B. https://ngcs-beta.staatsbibliothek-berlin.de/dc/871028646-0001/info.json) aber wird auch ein IIIF manifest unterstützt? (oder gibt es die Informationen nur via METS?)
Besten Dank
Peter Stadler
Hallo Herr Stadler,
schön zu lesen, dass Sie unsere IIIF-Schnittstelle nutzen möchten. Ein Manifest zu den einzelnen Objekten existiert und ist für das genannte Werk unter https://content.staatsbibliothek-berlin.de/dc/871028646/manifest verfügbar.
Wie aus der URL ersichtlich ist die Schnittstelle noch im Beta-Status. Eine beschreibende Dokumentation ist in Vorbereitung, die verschieden Möglichkeiten des Dienstes sind in der Dokumentation der Routen ersichtlich.
besten Gruß,
Marco Scheidhuber
Scheint ja überhaupt nicht zu funktionieren. Nichts wird gefunden. Chinesische Schriftzeichen, die bei Ostasiatika ja wohl nötig sind, scheinen auch nicht erkannt zu werden. Oder habe ich was falsch gemacht?
Hinweis
Na dann: Die Filter sind aktuell für diese Suche deaktiviert, weil eine Einschränkung über die Startseitenkategorien durchgeführt wurde. Wann kann man denn suchen?
Wenn man überhaupt keinen Filter einstellt, dann wir angezeitg, eine Liste, aber das Sutra ist nicht aufgegangen, internal Error steht da…
In welcher Form kann ich innerhalb von HTML-Dateien einen seitengenauen Link auf ein Digitalisat der StaBi legen? In diesem Fall „Code Napoléon … als Landrecht für das Großherzogthum Baden“. Diese URL wird für die Titelseite (Scanseite 5) angezeigt:
https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN663303400&%3BPHYSID=PHYS_0665&PHYSID=PHYS_0005&DMDID=
Wenn ich ihn allerdings aus der HTML-Datei heraus anklicke, werde ich nur zur ersten Seite (Einband) des Digitalisats geführt. Mit bestem Dank im Voraus für eine Antwort H. Speer
Hallo Herr Dr. Speer,
wenn Sie von der Seite aus, die sie verlinken wollen, oben den Werkzeugbereich öffnen (den Schraubenschlüssel) finden sie dann unten links in der Seitenleiste den Abschnitt „Bookmarks“ und dort dann „Persistente URL der Seite“.
Im konkreten Fall wäre das dann:
http://resolver.staatsbibliothek-berlin.de/SBB000053F000000005
When I try to download an entire manuscript (ZIP-Archiv des ganzen Bandes) I find that the zip file only includes about the first 200 images (the number varying from one ms to another, but for each always the same number of images for any particular ms). The last image is always defective. The rest of the images I can only download one-at-a time. Is there a maximum number of bytes which one can download at one time? Is there any way to download all the images at once? At least is there any way to download the remaining images many at a time?
Bei folgendem Digitalisat fehlen leider 2 Seiten, S. 42 & 43. Dafür ist S. 46 & 47 zweimal vorhanden: http://resolver.staatsbibliothek-berlin.de/SBB0000AF7E00000048
Die tatsächliche Seitenfolge ist also 41, 44, 45, 46, 47, 46, 47, 48, usw
Sehr geehrter Herr Wallis,
vielen Dank für den Hinweis – wir haben die Korrektur bereits veranlasst.
Viele Grüße
Ralf Stockmann
Sehr geehrter Herr Stockmann,
heute habe ich gesehen, dass die Fehler korrigiert wurden – vielen Dank dafür!
Eine Frage hätte ich noch: Gibt es eine Möglichkeit, dieses Werk als durchsuchbare PDF, also inklusive Volltext, herunterzuladen? Der DFG-Viewer verbindet ja beides, also muss es technisch möglich sein. Leider wird keine Download-Möglichkeit für den Volltext an sich unter dem Werkzeug-Symbol angeboten. Wenn ich also den Volltext haben wollte, müsste ich ihn seitenweise von der Webseite kopieren, was recht mühselige Arbeit ist und doch sicher vereinfacht werden kann – schließlich ist das in vielen Archiven bereits gang und gäbe.
Viele Grüße,
Roland Wallis
Sehr geehrter Herr Wallis,
doch, das geht: schauen Sie doch bitte mal in unserer runderneuerten Beta-Version der Digitalisierten Sammlungen vorbei, dort finden sie jetzt auch die Donwload-Möglichkeit:
https://digital-beta.staatsbibliothek-berlin.de/werkansicht?PPN=PPN73086863X&PHYSID=PHYS_0048&DMDID=DMDLOG_0003&view=picture-download
Weitere neue Funktionen der Beta werden hier beschrieben:
https://blog.sbb.berlin/formate-bilder-sicherheit-die-neue-beta-der-digitalisierten-sammlungen/
Viele Grüße
Ralf Stockmann
Sehr geehrter Herr Stockmann,
vielen Dank für den wertvollen Hinweis! Der Download der einzelnen XML-OCR-Dateien sowie der einzelnen Textdatei klappt. Wie füge ich jedoch nun OCR Dateien mit der PDF zusammen, dass meine PDF durchsuchbar wird? Gibt es keine Möglichkeit, die PDF direkt mit integrierter OCR herunterzuladen?
Viele Grüße,
Roland Wallis
Searching on a subject of interest as example „bread“ are a number of documents/books etc. offered.
It should be nice when one can make the same search after opening one of the selected documents/books.
See „Internationales archiv “
e the oeplcetion
Hallo,
https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN860029077&PHYSID=PHYS_0001
Leider kann ich auf den Brief von Edmond de la Fontaine nicht zugreifen. Das Dokument lädt überdurchschnittlich lange und zeigt die Bilder nicht an.
Wäre es möglich den Fehler zu beheben?
Vielen Dank im Voraus und mit freundlichen Grüßen,
Marlène Duhr
Hallo Frau Duhr,
vielen Dank für den Hinweis. Bei diesem Werk gab es einen Fehler beim Import in die Plattform.
Jetzt sind die Bilder verfügbar.
besten Gruß,
Marco Scheidhuber
Hallo Herr Scheidhuber,
Vielen Dank, einwandfrei lesbar.
Ich möchte noch auf einen Fehler in der Beschreibung aufmerksam machen:
Edmond de la Fontaine hat von 1823-1891 gelebt, der von Ihnen digitalisierte Brief ist aber auf 1897 datiert. Die Handschrift ist authentisch. Es kann sich nur um einen Fehler in der Datierung handeln. Nach näherer Betrachtung würde ich meinen, der Brief ist auf dem 15. Juni 1857 zu datieren.
Wie ist Ihre Meinung dazu?
Mit besten Grüßen,
Marlène Duhr
Hallo Frau Duhr,
danke für den Hinweis. Ich gebe die Frage an die Bibliothekar/innen weiter, welche die Metadaten erstellt haben.
besten Gruß,
Marco Scheidhuber
Sehr geehrte Damen und Herren,
zur Zeit scheint die Funktion „PDF des ganzen Bandes“ gestört zu sein, wenn man „Originale Scanauflösung“ wählt. Beispiel u.a. https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN771818300&view=picture-download; getestet mit Firefox 60.7.0 ESR und Chromium 73.0.3683.75 (Entwickler-Build) built on Debian 9.8, running on Debian 9.9 (64-Bit)). Es wird jeweils nur die erste Seite erzeugt, mit 2,7 MB Dateigröße, obwohl vorher „PDF mit 9 Seiten generieren. (ca. 13 MB).“ angekündigt wird. Am 2.6.2019 funktionierte noch alles wie erwartet (damals erfolgreich heruntergeladen: http://resolver.staatsbibliothek-berlin.de/SBB0001375F00000000).
Bei Auswahl von „Mittlere[r] Scanqualität“ und „Breite selbst wählen“ (ausprobiert mit 8000 px) wird die PDF-Datei mit allen zugehörigen Seiten erzeugt. Insofern kann ich mit meinem Projekt fortfahren, wollte den Hinweis trotzdem weitergegeben haben.
Freundliche Grüße
Bernhard Tempel
Nachtrag: Der beschriebene Workaround mit selbst gewählter Auflösung funktioniert zwar, allerdings werden die Seiten dabei durcheinandergewürfelt.
Sehr geehrte Damen und Herren,
noch ein Hinweis auf eine Ungereimtheit bei zwei Digitalisaten: Bei https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN771817312 fehlt die letzte Seite, die stattdessen am Anfang von https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN771817339 zu finden ist (dort auch die Reihenfolge nochmal zu prüfen).
Freundliche Grüße
Bernhard Tempel
Vielen Dank für Ihren Hinweis. Wir werden eine Korrektur der Präsentation beider Briefe anstoßen.
Freundliche Grüße
M. Federbusch
Hello,
I’m very interested in the Wenli Kangyur of which some volumes are available on your website, for instance
https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN1040798659&PHYSID=PHYS_0014&DMDID=
and I would like to be able to consult them in a iiif viewer. Do you provide a IIIF endpoint? If not, are you planning to implement that in the future?
Best,
—
Elie Roux
Lead Developer
Buddhist Digital Resource Center
Hello Elie,
yes we offer full iiif support. This is the link to the manifest:
https://content.staatsbibliothek-berlin.de/dc/1040798659/manifest
And this is our own iiif viewer:
https://mirador.staatsbibliothek-berlin.de/?manifest=https://content.staatsbibliothek-berlin.de/dc/1040798659/manifest
You’ll find them on our download-page:
https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN1040798659&PHYSID=PHYS_0014&view=picture-download
Best,
Ralf
Das Lichtbild von Karl August Varnhagen von Ense unter http://resolver.staatsbibliothek-berlin.de/SBB0001BBF500000000
stammt von Friedrich Wilhelm Halffter (1821–1901). Leipziger Str. 97 in Berlin.. jegór von Sivers ließ es nach Varnhagens ungedruckter Aufzeichnung vom 14.3.1853 an diesem Tag für einen Artikel in der Leipziger illustrierten Zeitung anfertigen. Eine schlecht abschattierte lithographierte Version wurde dort weniog später gedruckt (Bd. 21 (N. F. Bd. 9), Nr. 524 v. 16.7.1853, S. 40), vgl. Varnhagens Kommentar am 27.7.1853 in den gedruckten Tagebüchern, Bd. 10, 205.. Haffter hatte allerdings zwei Aufnahmen gemacht, bei der zweiten nahm V. seine Brille ab. Von dieser Variante liegt ein Exemplar in der Zentralbibliothek in Zürich im Nachlass Gottfried Keller. Ich selbst habe vor einigen Jahren diese Aufnahme irrig dem Hamburger Hermann Biow zugeschrieben, der Mitte Dezember 1847 in Berlin weilte und Varnhagen aufgenommen hatte (Tagebuch der Nichte Ludmilla Assing, 16.12.1847, Biblioteka Jagiellonska, Krakau, Samml. Varnh., Kasten 19). Die Biow’sche Aufnahme scheint verschollen zu sein, ebenso wie das Porträt der Dienerin „Dore“, Dorothea Neuendorf, das Biow ebenfalls anfertigte. In Krakau fehlt die letztere, die Ludwig Stern noch verzeichnet hatte. Vielleicht sind beide Biow’schen Porträtaufnahmen noch in der Bildnissammlung aufzufinden?
Dear Sir/Madam,
In the following digitization http://resolver.staatsbibliothek-berlin.de/SBB0000930500000000
page: 112v [228] is repeated in 113v [230]
page: 113v [230] is repeated in 114r [231]
Therefore, the numbering between [230] until [242] does not reflect reality of the manuscript.
More importantly, pages 118v and 119r are missing (using correct numbering)
Using current numbering: two pages are missing in between [242] and [243].
Many thanks for reviewing this matter!
Thank you for pointing that out. The error is known and the work is currently under revision.
Best regards,
Marco Scheidhuber
Sehr geehrte Damen und Herren,
bei http://resolver.staatsbibliothek-berlin.de/SBB0001378600000000 fehlen einige Seiten, die stattdessen am Anfang von
http://resolver.staatsbibliothek-berlin.de/SBB0001378700000000 zu finden sind.
Freundliche Grüße
Bernhard Tempel
Lieber Herr Tempel,
auch diesen Scanfehler werden wir berichtigen. Danke für den Hinweis. Bis Sie die Korrekturen sehen, kann es allerdings ein paar Tage dauern.
MfG
M. Federbusch
Sehr geehrte Damen und Herren,
ich habe die Musikhandschrift in Digitalsammlung gefunden:
Kaczkonski, J.: Rondeau à la Polonoise [!] pour Le Pianoforte , 1815
Ich sehe, dass diese polnische Name nich Kaczkonski, aber Kaczkowski ist.
Beste Gruesse,
Joanna Gul
Liebe Frau Gul,
es handelt sich bei der Namensform Kaczkonski um die Vorlageform auf dem Musikdruck. Lange Zeit haben wir diese als Metadatum dem Digitalisat mitgegeben. In unserem Katalog ist alles korrekt:
http://stabikat.de/DB=1/XMLPRS=N/PPN?PPN=799363235
Momentan überarbeiten wir unsere Konfigurationen, um anschließend alle unsere METS-Daten zu aktualisieren. Ich habe das jetzt in Ihrem Beispiel schon einmal manuell gemacht. Die Änderung sollten Sie in den nächsten Tagen sehen.
Mit freundlichen Grüßen
M. Federbusch
Liebe Frau Federbusch,
Vielen Dank für die Klarstellung. Mit freundlichen Grüßen
Joanna Gul
Hallo! Ich vermisse unter der Sammlung zur PPN722221258 Band 6, 2. Hälfte, April bis Juni 1917. Wird die noch digitalisiert oder wurde sie vielleicht vergessen?
Viele Grüße,
Roland Wallis
Hallo Her Wallis,
nach Rücksprache mit der Fachabteilung wurden diese Werke im Rahmen des Projektes „Europeana 1. Weltkrieg“ bis 2014 digitalisiert. Daher ist eine Digitalisierung mehr als unwahrscheinlich. Da ich Band 6, 2. Hälfte auch im Stabikat nicht finde, vermute ich, dass dieser nicht in der SBB vorhanden ist.
besten Gruß,
Marco Scheidhuber
Hallo Herr Scheidhuber! Danke für die Auskunft. Wenn es ein Projekt war, wurde dieser Band entweder vergessen oder sollte aus bestimmten (wahrscheinlich politischen) Gründen nicht digitalisiert werden. Anders ergibt es für mich keinen Sinn, warum man bei der Serie „Der Europäische Krieg in aktenmäßiger Darstellung“ sämtliche Bände 1-9 und sogar Zusatzbände digitalisiert hat, nur den einen erwähnten nicht:
Band 1 – Juli-Dez. 1914 (Beginn 1. WK)
Band 2 – Jan.-Juni 1915
Band 3 – Juli-Dez. 1915
Band 4, 1. Teil – Jan.-März 1916
Band 4, 2. Teil – Apr.-Juni 1916
Band 5, 1. Teil – Juli-Sept.1916
Band 5, 2. Teil – Okt.-Dez. 1916
Band 6, 1. Teil – Jan.-März 1917
Band 6, 2. Teil – April-Juni 1917 (fehlt)
Band 7, 1. Teil – Juli-Sept. 1917
Band 7, 2. Teil – Okt.-Dez. 1917
Band 8, 1. Teil – Jan.-März 1918
Band 8, 2. Teil – Apr.-Juni 1918
Band 9, 1. Teil – Juli-Sep. 1918
Band 9, 2. Teil – Okt.-Dez. 1918 (Ende 1. WK)
Soll mich aber nichts angehen, ich habe mir den fehlenden Band via Google Books besorgt. Hat zwar miserable Qualität, reicht aber fürs Wesentliche.
Liebe KollegInnen, die RSS-Feeds funktionieren seit geraumer Zeit nicht! Bitte kümmern Sie sich doch zeitnnah darum,. ich benutze die sehr häufig. Dank & Gruß, Falk Eisermann (IIIA)
Lieber Herr Eisermann,
entschuldigen Sie die peinlich späte Rückmeldung. Wenn das Problem weiterhin besteht, bitte ich um eine genauere Beschreibung, ich sehe unter https://digital.staatsbibliothek-berlin.de/feeds die einzelnen Feeds, die auch die aktuellen Werke enthalten.
besten Gruß,
Marco Scheidhuber
Ich vermisse eine Möglichkeit, von einem Dokument in der Sammlung (Gesetz-Sammlung …) auf die Auswahlseite für die Bände der Sammlung zurückzukehren. Das geht — wenn ich nichts übersehen habe — nur durch ein erneutes Laden der Grundseite vom Katalog aus. Langwieriger Umweg. — Aber danke, dass es das überhaupt gibt …
Lieber Herr Haselbach,
auf der Info-View eines Bandes (https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN783145500&PHYSID=PHYS_0005&view=overview-info) finden Sie einen persistenten Link auf das mehrbändige Werk, das die einzelnen Bände erhält. In diesem Beispiel ist das http://resolver.staatsbibliothek-berlin.de/SBB0000D40100000000. Wenn Sie von dieser Liste aus einen Band aufrufen, kommen Sie sowohl über den Zurück-Button des Browsers, als auch über den Button Schließen auf der Werkansicht oben rechts, auf diese Übersicht zurück.
besten Gruß,
Marco Scheidhuber
Guten Tag,
Mir ist ein Fehler aufgefallen:
Der Autor Giuseppe La Farina erscheint als „Guiseppe“
S. La China Considerata Nella Sua Storia, Ne‘ Suoi Riti, Ne‘ Suoi Costumi, Nella Sua Industria, Nelle Sue Arti E Ne‘ Più Memorevoli Avvenimenti Della Guerra Attuale
https://digital.staatsbibliothek-berlin.de/suche/?queryString=aut:La%20Farina,%20Guiseppe
Danke!
Mit freundlichen Grüßen
Chiara Bocci
Liebe Frau Bocci,
vielen Dank für Ihren Hinweis, den ich zum Bearbeiten weiterleite.
Bitte beachten Sie, dass es ein paar Tage dauern kann, bis der Fehler in allen
Werken bereinigt und wieder in den Digitalisierten Sammlungen eingespielt ist.
vielen Dank und besten Gruß,
Marco Scheidhuber
Liebe Frau Bocci,
die Änderungen sind bereits aktiv, siehe https://digital.staatsbibliothek-berlin.de/suche/?queryString=aut:La%20Farina,%20Giuseppe
besten Gruß,
Marco Scheidhuber
Ich bekomme nur Ergebnisdateien, in denen die erste Seite (das erzeugte Vorblatt) lesbar ist, nicht aber die bestellten Seiten.
Die Datei ist aber zu groß, um nur eine Seite zu enthalten.
Einzelheiten und eine Belegdatei können Sie gerne per Mail anfordern, ich habe den Weg meines Scheiterns schon für die UB Gießen beschrieben.
Außerdem sehe ich in der Ansicht keine der gescannten Seiten. Der Lese/Vorschaubildschirm ist schwarz.
Bei einem anderen Nutzer, einem Mitarbeiter der UB, der mein Scheitern mit einem Privataccount von zu Hause nachvollziehen wollte, sind diese Probleme nicht aufgetreten.
Hallo
Vielen Dank für die Digitalisierung dieses Werkes. Leider sind die Knöpfe unter dem Titel „Volltext“ ausgegraut. Ja ich weiss, das heisst, dass es keine Transkription dieses Werke gibt. Es wäre toll, wenn mit https://transkribus.eu/Transkribus/ dieses Werk als Elektronischen Text zur verfügung gemacht würde.
Grüsse
Fabian
Hello, some works written in ghotics are also available with a parallel text in Latin letters. Is it possible for this text and how in this case to obtain it? If it is not the case, do you know a program transcribing from ghotoqies to Latin letters? Thank you very much. Boris Czerny. Mit der Heeresgruppe des Prinzen Leopold von Bayern nach Weißrussland hinein : Kriegsberichte / von Wilhelm Feldmann
Dear Mr. Czerny,
the texts in the digitized collections was created via Optical Character Recognition and the fracture letters are transformed into unicode that is presented with a good readable font for all works.
Is the work https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN679530967&PHYSID=PHYS_0025&view=fulltext-parallel&DMDID=DMDLOG_0001 the one you are looking for? You can just get the text for it here in the reading mode or download the whole thing. But maybe I miss the point you are looking for.
Best regards,
Marco Scheidhuber
Liebe KollegInnen, Download TIFF u.a. funktioniert nicht z.B. bei https://content.staatsbibliothek-berlin.de/dc/download/zip?ppn=PPN789851954 (Internal Server Error). Mit freundlichen Grüßen, Christian Thomas
Lieber Christian Thomas,
danke für die Fehlermeldung. Das wurde gefixt und dann ist die Rückmeldung untergegangen. Hiermit nachgeholt, bitte um Entschuldigung.
besten Gruß,
Marco Scheidhuber
Hello, there is a problem with MS. 62 „Vocabularies of the language spoken in the Isles of the South-Sea“, images are not loading.
Hi Roman Beauclerc,
are you looking at https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN1025514785&PHYSID=PHYS_0005? Images are loading fine, but there was some trouble with the servers last weekend. Please try now, should work fine.
Best regards,
Marco
Der Download wird quälend langsam vorbereitet und hängt sich dann bei 99% auf. Nichts geht mehr. Das passiert auch bei anderen Downloads der Digitalisate. Das habe ich schon vor 2 Jahren bemängelt, und nichts hat sich seitdem getan!!! Eine Blamage für die Staatsbibliothek von Deutschland!!!
Lieber Herr Szilagyi,
um Ihnen besser helfen zu können, schreiben Sie uns bitte welches Werk sie herunterladen möchten und welchen Download Sie meinen (ich vermute als PDF?).
besten Gruß,
Marco Scheidhuber
Dear M Scheidhuber,
I am very grateful to be able to find the this score online.
https://digital.staatsbibliothek-berlin.de/werkansicht/?PPN=PPN1016294719
However, according to the Catalogue made by Adolf Meier in 1990, states that this manuscript contains the movement change from the initial Adagio to an Allegro in the first movement. That means that there are several pages missing.
It’s stated that the original at
SBB Berlin KHM 5240
has 64 pages, whereas the digital copy has only 38. Some of the missing will be irrelevant, but there is the end of the introductory adagio and almost the full exposition of the symphonie’s first movement missing.
Also, there is a paging in pencil at the corners that make think they’ve been added once arrived to a modern library, p.e. 2-19, 22-23 missing.
Before I make a request for a complete copy at the reproduction services, do you think this could be edited-corrected in the online version? Thank you very much
Nabi Cabestany
I found out that going to Übersicht, one can actually choose to download the total amount of pages, also at a higher resolution, where all the pages will appear. Thank you
Dear Mr. Cabestany,
as I see 64 pages in the digital copy here in the digitised collections I can’t see the missing parts. However, I forward your question to our music department and get back to you.
Best regards,
Marco Scheidhuber
Lieber Herr Scheidhuber,
schaue mir gerade die METS/MODS-Metadaten an, am Beispiel von Tagebuch II und VI von AvHs Reise durch die amerikanischen Tropen (http://resolver.staatsbibliothek-berlin.de/SBB0001527300000000).
Mich würde sehr interessieren, wie Ihr Metadaten-Workflow aussieht, bzw. konkreter
1) welche Software benutzen Sie zur Erfassung der METS-Daten, und
2) gibt es eine Art Lastenheft für die Mitarbeiter*innen, die die Daten erstellen? Und würden Sie
3) dieses vielleicht sogar zur Nachnutzung und als Lern- und Lehrmaterial für andere zur Verfügung stellen?
Beste Grüße,
Tobias Kraft
Lieber Herr Kraft,
unseren Digitalisierungsworkflow finden Sie auf der Seite der Digitalisierten Sammlungen unter:
https://digital.staatsbibliothek-berlin.de/ueber-digitalisierte-sammlungen/digiworkflow
Die Fragen, ob es ein Art Lastenheft für die Mitarbeiter gibt und dieses zur Verfügung gestellt werden kann, reiche ich weiter. Ich erhalte die METS-Dateien bereits mit Struktur- und Metadaten und verabeite sie für die Präsentation weiter.
besten Gruß,
Marco Scheidhuber
Lieber Herr Kraft,
gern will ich die Ausführungen meines Kollegen ergänzen:
a) Wir arbeiten mit der Workflowsoftware Kitodo 2.3
b) Wir haben grundsätzliche Anweisungen bzgl. der einzelnen Workflowschritte, die projektspezifisch ergänzt werden können. Diese Papiere fußen auf den Praxisrichtlinien der DFG bzw. den Vorgaben des Anwendungsprofils für digitalisierte Medien (http://dfg-viewer.de/metadaten) oder dem Strukturdatenset (http://dfg-viewer.de/strukturdatenset).
c) Bzgl. der Weitergabe von Papieren reiche ich Ihr Anliegen an unsere AG Workflow weiter. Dazu wäre es hilfreich zu wissen, welche Bereiche Sie besonders interessieren.
Sehr geehrte Damen und Herren, ist das Digitalisat der Humoresken von Emilie Meyer nicht herunterladbar? Es ist so schwerig, den Computer auf das Klavier zu stellen… Freundliche Grüße, Albert Raffelt
Lieber Herr Raffelt, der Computer muss nicht auf das Klavier. Gehen Sie in der Werkansicht oben in der Menüleiste auf den kleinen Schraubenschlüssel (Werkzeugkasten) und unten bekommen Sie verschiedene Download-Möglichkeiten.
Liebe Bibliothekenteam,
seit über 40 Jahren forsche ich nach meinen Vorfahren. Mein Großvater war im 1. WK im Bereich der Bugarmee. Mit Ihren Digitalisaten habe ich ihn gefunden. Nun ist leider die „Feldzeitung der Bugarmee , 1916“ so groß (über 6GB), dass diese nicht abgespeichert und dann geöffnet werden kann. Können Sie diese Zeitung in zwei Zeitungen teilen und abspeichern?
Mit freundlichem Gruß
Gerhard Kreile
Sehr geehrter Herr Kreile, auch Ihnen hilft die Differenzierung des Downloads über den Werkzeugkasten. Wählen Sie in der Menüleiste oben den Schraubenschlüssel (Werkzeugkasten) und Sie erhalten etwas weiter unten die Möglichkeit, einzelne Teile des Werkes auszuwählen und herunterzuladen.
https://digital.staatsbibliothek-berlin.de
/werkansicht?PPN=PPN1726631397&PHYSID=PHYS_0005&DMDID=h
Sehr geehrte Damen und Herren,
Ich habe zwar schon einmal mitgeteilt, dass der Brief nicht an unbekannt ging, sondern an den wohlbekannten Professor Karl Weinhold der Berliner Universität, was sich aus dem Inhalt zweifelsfrei ergibt.
Vielleicht wird es ja mal geändert!
Frdl. Gruß
Hans Fix-Bonner
Wir haben Ihre Anmerkung an die zuständigen Kollegen der Handschriftenabteilung weitergeleitet.
Beste Grüße von
M. Federbusch
Hallo,
beim Download von Musik-Handschriften gibt es einen immer wiederkehrenden Fehler, als Beispiel sei:
https://digital.staatsbibliothek-berlin.de/werkansicht/?PPN=PPN1726083454
genannt.
Wenn man auf „Download pdf“ klickt und dann „pdf des ganzen Bandes“ auswählt wird im ersten Versuch immer nur die erste Seite als pdf geliefert.
Erst beim Wiederholen klappt es.
So war es bei allen anderen Werken auch.
HG Peter Wuttke
Liebes Team, ich suche zwischen den Zeilen und unter der Oberfläche. Es geht um Pressemeldungen, Desertierten- und Vagabundenlisten u.ä. Mein direkter Vorfahre, ein frz. Soldat aus Guadeloupe (Mai 1802) ist aus Mantua mit einer Gruppe desertiert. Pressemeldung Bozen 30.09.1804 in einer englischsprachigen Zeitung. Die Gruppe will über den Brenner, eigentlich nach Wien. Aber Tirols und Salzburgs Grenzen schließen Wege einer Gelbfieberepidemie Ende November 1804 für einige Monate bis mindestens März 1805. Also sind sie vorher durchgekommen. Ankunft in Plön 1.9.1805. Ich stelle mir die Route vor Brenner – Innsbruck – München – …. nach Norden (mehrere Varianten möglich, Rheinschiene auf keinen Fall), nördlich Hannover frz. Regimenter durchquert und nicht aufgeflogen, vermutlich bei Zollenspieker über de Elbe und Bergedorf Wandsbek Lübeck, sie wollten nach Travemünde, aber schon gesperrt, in Lübeck sind sie aufgeflogen durchgemeldet und von den Franzosen bis ins holsteinisch dänische Gebiet verfolgt und bei Stockelsdorf ziehen lassen, Ankunft in Plön 1.9.1805 morgens. Ich suche noch Zeugnisse und Listen der Truppe unterwegs. In Bozen waren es noch 10 Leute, in Plön eine Gruppe, die gerade in eine Kutsche passt. Der Weg von Bozen(eigentlich Mantua) – Plön dauerte also en Jahr. Für weitere Ideen wäre ich dankbar. In Mantua auch Zusammenarbet mit englischem Geheimdienst , da stand die Menschlichkeit hoch, um den farbigen Soldaten zu helfen ud Frankreich zu schaden.
Haben Sie Ideen, wo ich noch Quellen finden könnte? Kam mit „deutschen“ Zeitungen 1804-1805 nicht sehr weit. Mit freundlichen Grüßen Sandra Willendorf
Liebe Frau Willendorf,
ich kann an dieser Stelle auf das Zeitungsinformationsportal ZEFYS verweisen, vielleicht finden Sie dort weitere Hinweise: https://zefys.staatsbibliothek-berlin.de/kalender/
Ansonsten hoffe ich, dass hier noch weitere Ideen für Ihre Recherche kommen.
besten Gruß,
Marco Scheidhuber
Sehr geehrte, ich probiere diese link zu öffnen, aber das geht nicht. Können Sie mir bitte Hilfen? Sorry, aber ich spreche kaum Deutsch, aber verstehe es.
https://stabikat.de/CHARSET=UTF-8/DB=1/LNG=DU/CMD?ACT=SRCHA&IKT=1016&SRT=YOP&TRM=Schriftprobe%20Giovanni%20Paisiello%20(1762)
Sehr geehrter Herr Couvreur,
jetzt sollte der Aufruf zu einem Ergebnis führen. Bitte probieren Sie erneut.
Freundliche Grüße!
Der 1593er Druck der Grammatica Latina war bis vor Kurzem abrufbar unter https://digital.staatsbibliothek-berlin.de/wersekansicht/?PPN=PPN1750815354 .
Jetzt nicht mehr. Ist das nur vorübergehend oder gibt es ein Problem dabei?
Liebe Frau Kärnä,
der von Ihnen genannte Link enthält einen Tippfehler, das Digitalisat steht unter dem korrekten Link nach wie vor zur Verfügung: https://digital.staatsbibliothek-berlin.de/werkansicht/?PPN=PPN1750815354
Beste Grüße!
Sehr geehrte, Staatsbibliothek zu Berlin – Preußischer Kulturbesitz
Fragm. 259 ist genannt ‚Selenspiegel‘. Es sollte aber ‚Der leken spiegel‘ sein (mein PhD handelt über Der leken spiegel).
Freundliche grüsse,
Era Gordeau
Wir kümmern uns um eine Korrektur.
Mit freundlichen Grüßen
M. Federbusch
Dear sir or madam,
I just tried to download one of the digitised manuscripts from the Digitalisierte Sammlungen (a file of about 200 mb in total), and this process severely slowed down my computer, eventually forcing me to shut it down after I was not able to do anything else on my laptop for half an hour. I am using Firefox on Mac. Although there is a warning message about the process possibly „freezing“, this seems really out of bounds. I think this function really needs to be looked at and improved — no other digital libraries I know of (for example Gallica, Bayerische StaBi, Qatar National Library, etc.) require so many resources from the computer as to completely freeze everything for downloading a file that is in fact not exceptionally large. This is unfortunate, as the scans provided are of high quality but would be easier to work with in a PDF reader rather than the online reader.
Many thanks in advance for addressing this issue.
Best wishes,
Gowaart
Dear Gowaart,
I’m sorry that the production of an pdf-file is not working for you. The process of building the pdf is on client side, completely in your browser, whats the reason that especially enough RAM is needed. The decision to build the pdf with client side processing was mostly due to the GDPR. I will take your comment as base for a further discussion in the tech team.
For now I can offer that you send me an email (marco.scheidhuber@sbb.spk-berlin.de) and I create the pdf file and send you a link for a direct download.
Best regards,
Marco
Sehr geehrte Damen und Herren,
Bei der Nützung von gewisse digitalisierte Bücher, besonders der ‚Almanak en Naamregister Nederlands Indië 1856‘ empfinde ich eine Störung beim Durchblättern ab Seite [453]-361.
Vielleicht werde ich das aug begegnen in andere Jahrgänge. Das werde ich überprüfen. Bis dahin hoffe ich dass Sie mich informieren können, was ich tun sollte.
Im voraus vielen Dank.
Frans Super
Niederlande
frans.super@hotmail.com
Leider lädt die Leichenpredigt von Johann Volck nicht, alles bleibt schwarz.
Können Die mir bitte ein pdf der LP mailen? danke SZ.
Sehr geehrter Herr Ziesenitz,
die Leichenpredigt steht vollständig zur Verfügung. Leider gibt es gelegentlich Anzeigeprobleme in den Digitalisierten Sammlungen. Hier kann die Nutzung eines anderen Browsers helfen. Auch das pdf können Sie unproblematisch (da nicht zu umfangreich) selbst erstellen.
Mit freundlichen Grüßen,
Maria Federbusch
Es lassen sich nur die ersten beiden Seiten des Bandes Mattei, Pratica Bd. 1, Ricordi anschauen, weiteres Blättern ist nicht möglich. Der Blindstempel auf den Titeln gibt [19]06 an, evtl. für die Datierung zu berücksichtigen. VG, AS
Sehr geehrter Herr Staub,
vielen Dank für den Hinweis – da hatte sich offensichtlich bei der Schlussbearbeitung des Digitalisates ein Fehler eingeschlichen. Wir werden dies zeitnah korrigieren, so dass der Band dann demnächst vollständig durchblätterbar sein wird.
Mit freundlichen Grüßen
Roland Schmidt-Hensel
Moin zusammen,
Als Hinweis gedacht, der Download als pdf Buch für „Heimatgruß aus Soest , 1918“ klappte trotz laufenden Fortschrittbalkens nicht.
https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN770551009&PHYSID=
Gruß aus Soest
Jürgen Wexel
Sehr geehrter Herr Wexel,
ich habe soeben unproblematisch ein pdf des besagten Bandes heruntergeladen und gehe davon aus, dass Sie inzwischen auch erfolgreich waren und das offenbar temporär aufgetretene Problem nicht mehr besteht.
Mit freundlichen Grüßen
Maria Federbusch
Danke, ja hat soeben gut geklappt !
Leider bricht der Download in Originalauflösung immer bei 99% bis 100% ab, egal wieviele Seiten ich einstelle (gesamt, 500 Seiten, 400 Seiten, 200 Seiten, 100 Seiten). Auf meiner Seite ist genug Rechen- wie Arbeitsspeicherkapazität vorhanden.
Vielen Dank für den Hinweis! Wenn Sie uns die PPN nennen, können ggf. wir den Export übernehmen und Ihnen das gewünschte Werk als PDF-Datei zum Download zur Verfügung stellen.
Ich hatte den Link:
https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN1777520959&PHYSID=PHYS_0011&DMDID=&view=picture-download
benutzt. Wenn Sie mir das komplette PDF in der Original-Scanauflösung bereitstellen könnten, wäre ich sehr dankbar!
Herzlichen Dank! Sie erhalten eine Mail.
Hallo, ich nutze mit großer Begeisterung Ihre Digitalisate. Aber wenn ich ganze Werke als PDF herunterlade, werden alle oder min. viele Seiten nur als schwarze Flächen heruntergeladen. Die Dateigröße weist schon darauf hin, dass hier etwas nicht stimmt. Ich kann zwar die Seiten als ZIP-Archiv laden und Ann die einzelnen JPGs zu einer PDF zusammenführen, das ist aber umständlich. Können Sie den Bug fixen? Danke!
Vielen Dank für die Mitteilung! Das Problem ist uns bekannt und wir bemühen uns um eine Lösung.
Liebes Team,
wäre es möglich, die Kapitel der Gliederung in den PDF-Download aufzunehmen? Bei Werken von großem Umfang (bspw. JS Bach, Matthäus-Passion) würde dies den Umgang und die Orientierung enorm erleichtern.
Lieber Musician,
das von Ihnen gewünschte Feature existiert bereits. Wenn Sie das zweite Icon in der Menüleiste anklicken, gelangen Sie in eine Darstellung des Inhaltsverzeichnisses. Jede dort aufgeführte Einheit ist einzeln als PDF herunterladbar. Das funktioniert auch bei der Matthäuspassion; ich habe es soeben noch einmal ausprobiert.
Mit freundlichen Grüßen
M. Federbusch
Guten Tag in der Staatsbibliothek,
ich möchte mich sehr bedanken für die Digitalisierung der beiden so bedeutenden Musikhandschriften, Quedlinburger Antiphonale und Graduale, D-B Mus. ms. 40047 und 40078. Das ist wirklich großartig für den Erhalt der kostbaren Bücher und für die musikwissenschaftliche Arbeit (ich nutze das Digitalisat gerade für vergleichende Arbeiten) und die Möglichkeit, diese Quellen auch für aufführungspraktische Zwecke zu konsultieren. Ich bin wirklich glücklich darüber. Eine Frage: Ist das Indexierungsdatum also das Datum, als die Digitalisate ins Netz gestellt wurden? Nochmals vielen Dank für diese hilfreichen Mühen der Digitalisierung, in denen ich Sie weiter bestärken möchte. Und ich hoffe auch, Ihnen bleiben weiterhin Mittel für solche Arbeit.
Herzliche Grüße,
Ellen Hünigen
Ich habe noch an die vorige Mail anschließend eine Frage zur digitalisierten Handschrift D-B Mus. ms. 40047, zum Quedlinburger Antiphonar: In den Informationen zum Digitalisat steht zur Datierung der Handschrift 1000-1050. Bei Hartmut Möller, der viel über diese Handschrift gearbeitet hat, las ich 1025-1070, ebenso auf Cantus Database, die sich wohl auch auf Möller stützen. Können Sie Hinweise geben, warum man zu der anderen Datierung als Möller gekommen ist? Gäbe es die Möglichkeit des Kontaktes zu derjenigen Person, die zu der anderen Datierung gekommen ist?
Vielen Dank,
mit freundlichen Grüßen,
Ellen Hünigen
Sehr geehrte Frau Hünigen,
vielen Dank für Ihren Hinweis zur Datierung der Handschrift Mus.ms. 40047. Bekanntlich sind Datierungsversuche mittelalterlicher Handschriften häufig mit einer gewissen Unschärfe befrachtet, was auch für diese Quelle zutrifft. In diesem Falle ist zusätzlich zu beachten, dass die Quelle aus zwei unabhängig voneinander entstandenen Teilen besteht – dem Kalendar auf Bl. 1-6 und dem eigentlichen Antiphonar ab Bl. 7.
Wenn ich die Angaben bei Möller recht interpretiere, bezieht er die Datierung 1025-1070 explizit nur auf das Kalendar (s. S. 32ff.), wohingegen zum Antiphonar vermerkt wird, dass „der zeitliche Ansatz […] vorerst auf die ungefähre Angabe: 1. Hälfte des 11. Jahrhunderts beschränkt bleiben“ muss (S. 44, ebenso die Zusammenfassung S. 187). Ich werde dies in der knappen Quellenbeschreibung unter https://opac.rism.info/search?id=466000329&View=rism noch etwas stärker differenzieren, die Datumsangabe in den Digitalisierten Sammlungen aber einstweilen so belassen.
Das in den Metadaten angegebene Indexierungsdatum bezeichnet in der Tat das Datum der (letzten) Einspielung in unsere Digitalisierte Sammlungen. Meist dürfte dies auch identisch sein mit dem Datum der erstmaligen Online-Stellung; im konkret vorliegenden Fall wurde das Digitalisat aber aus technischen Gründen im Sommer 2022 neu importiert. Aus anderen Indizien lässt sich aber grob rekonstruieren, dass Mus.ms. 40047 und 40078 höchstwahrscheinlich im 2. Halbjahr 2014 online gestellt wurden.
Mit freundlichen Grüßen
Roland Schmidt-Hensel
Sehr geehrte Damen und Herren,
leider kann ich kein PDF des ganzen Bandes herunterladen. Wiederholte Versuche ergaben eine PDF-Datei im Umfang von 3,3 MB , die aus lauter schwarzen Seiten besteht. Download der 616 MB tifs klappt, aber das wollte ich eigentlich nicht. Was ist da passiert?
Vielen Dank und Grüße,
— Günther Görz
Sorry, ich hatte die URL aus Versehen unter Website angegeben:
https://digital.staatsbibliothek-berlin.de/werkansicht?PPN=PPN167210646X&view=picture-download
Es handelt sich um Ms. Ham. 396
Vielen Dank für den Hinweis! Ihr Anliegen ist in Bearbeitung und wir werden Ihnen zeitnah antworten.
„Massmann, Hans F.: Brief an Jacob Grimm : 24.09.1929 , 1929“
M.E. wäre 1829 plausibler (Grimm +1863, Maßmann +1874)
Ich kümmere mich um Korrektur.
您好,此網頁中的中國《堂邑縣志》20卷,刊刻時間著錄爲1892年,即清光緒十八年。經對比發現貴館所藏非1892年刊本,應為1711年清康熙五十年刻,1736-1796年乾隆年間後印本。這個版本比較少見,版本價值高。但貴館僅公佈了幾頁影像,能否發送此書的全部影像。感謝貴館。
Dear Lü Zhengchuan
allow me to reply to you in English. Thank you for pointing out, that we might have wrongly identified the edition of the 堂邑縣志 (Libri sin. N.S. 96)! The title was not fully digitized because the Beijing National Library’s digital collection appeared to have the same edition freely available online – something I cannot check right now because read.ncl.de is currently not accessible. I can confirm your observation that all of the 1892 editions (those I can find online in Harvard or in commercial databases accessible to Staatsbibliothek and CrossAsia users) are different … Is the 後引 edition you name online available somewhere?
As a result of the Second World War, the book is not in Berlin anymore and is now in the Biblioteka Jagiellońska, Kraków with whom we cooperatively did this digitization project in 2013/2014 (https://themen.crossasia.org/berlin-krakow/?lang=en). We will contact the colleagues in Poland inquiring the possibility to digitize the complete title. We will keep you updated via email.
Best regards,
Martina Siebert
Ich suche nach einer Möglichkeit, die angezeigten digitalisierten historischen Kinderbücher nach E-Jahr zu ordnen – können Sie mir einen Tipp geben?
Auf jeder Suchergebnisseite (e.g. https://digital.staatsbibliothek-berlin.de/suche?queryString=categories%3A%22Kinder-%20und%20Jugendb%C3%BCcher%22%20project%3Acolibri&fulltext=&junction=&feature=colibri&results_on_page=20¤t_page=1&sort_on=year&sort_direction=desc) sollten Sie unmittelbar über dem ersten Suchergebnis die Paginierungsleiste zum Durchblättern der Ergebnisse finden. Am rechten Rand der Paginierungsleiste sollten Reihenfolge und Kriterium der aktuellen Sortierung angezeigt sein, beispielsweise „Absteigend“ sowie „Relevanz“. Auch wenn es zunächst nicht danach aussieht, kann mit diesen Indikatoren durch Draufklicken interagiert werden. Unter anderem können Sie auf diese Weise auch nach Erscheinungsjahr sortieren (URL-Parameter „&sort_on=year“).
Liebes Stabi-Team
Bei den Downloadoptionen kommt seit einigen Tagen immer die Fehlermeldung „Ihre Seitenangabe ist ungültig, der Seitenbeginn muss kleiner oder gleich dem Seitenende sein und beide Angaben dürfen nicht 0 sein.“, obwohl es keinen Fehler bei den Angaben zum Seitenanfang und Seitenende gibt. Was könnte hier der Fehler sein? Vielen Dank im Voraus und freundliche Grüsse!
Vielen Dank für den Hinweis! Wir haben den Fehler korrigiert.