Seit wann gibt es „Stadt, Land, Fluss?“ Mit Stabi-Daten und KI Antworten finden
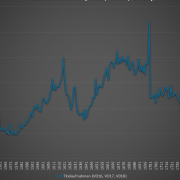
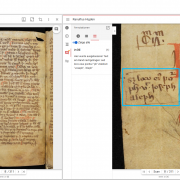
Schon richtig – es gibt vermutlich wichtigere Recherchefragen. Andererseits: Wenn man in der Familie gerne „Stadt, Land, Fluss“ spielt, kann man schon einmal nach der Herkunft des Spiels fragen. Tarek Saier hat Antworten dazu gefunden und dabei einen von der Staatsbibliothek zu Berlin publizierten Datensatz verwendet. Die kurze Antwort lautet: Das Spiel „Stadt, Land, Fluss“ […]