
Kuratieren mit KI: Erste Ergebnisse aus dem QURATOR-Projekt
Ein Beitrag aus unserer Reihe Künstliche Intelligenz zum Wissenschaftsjahr 2019
QURATOR ist ein BMBF-gefördertes Forschungsprojekt mit dem Ziel, ein weites Spektrum von Kuratierungstechnologien basierend auf Methoden und Verfahren der künstlichen Intelligenz zu entwickeln. Wir haben hier im Blog schon mehrfach zum Projekt berichtet. Nachdem im November 2019 das erste von insgesamt drei Jahren Projektlaufzeit endete, liegen inzwischen auch Zwischenergebnisse von insgesamt drei Aktivitäten aus dem Arbeitsbereich der SBB „Digitalisiertes kulturelles Erbe“ vor, die wir Ihnen hier gerne kurz vorstellen wollen.
Qualitätsverbesserung OCR
Eine grundlegende Voraussetzung für Suche, Recherche, Analyse und Verarbeitung von digitalisierten Dokumenten sind qualitativ hochwertige, automatisch durch OCR (Optical Character Recognition) erzeugte Volltexte. Während sich die SBB parallel im DFG-Projekt OCR-D vor allem im Bereich der Spezifizierung von offenen Schnittstellen und Datenformaten für die OCR einbringt, wird im Rahmen von QURATOR durch die SBB auch an der Verbesserung der Qualität von OCR Ergebnissen gearbeitet. Hierzu wurden auf dem Datenset GT4HistOCR (Springmann et al., 2018) mehrere Modelle für die auf Deep Learning basierende OCR-Engine Calamari (Wick et al., 2018) trainiert. Eine Besonderheit von Calamari im Vergleich zu anderen OCR-Engines liegt darin, dass bei der OCR mit mehreren Modellen parallel gearbeitet wird, die anschließend in einem Voting-Verfahren unter den Modellen das optimale Ergebnis ermitteln.

Voting der OCR Modelle
Um dies an einem Beispiel zu illustrieren: im folgenden wird mit drei OCR-Modellen gearbeitet. Während Modell 1 (blau) hier mit 80% Sicherheit ein „i“ erkennt, tendieren die Modelle 2 (violett) und 3 (grün) als erste Option für den auf „Beyſp…“ folgenden Buchstaben mit 40% resp. 30% zu einem „i„.
Die Modelle 2 und 3 geben hingegen eine höhere Wahrscheinlichkeit (50% resp. 40%) für die zweite Option „l“ an. Bildet man aber nun aus sämtlichen Modellen für jede erkannte Variante mit deren Konfidenzwerten die Summe, so ergibt sich letztlich doch die Ausgabe des „i“ als beste Möglichkeit. Dies liegt daran, dass das Modell 1 sich hier besonders sicher ist, auch wirklich ein „i“ erkannt zu haben (80%).
So lässt sich letztendlich zeigen, dass die Modelle unterschiedliche Merkmale unterschiedlich gut lernen, und durch Kombination der Spezialisierungen der Modelle im Gesamtergebnis eine höhere Qualität erzielt werden kann.
Erste Tests im Vergleich mit der aktuellen Version 4.1 der Open Source OCR-Engine Tesseract und dem Standard-Modell für Fraktur (frk) deuten darauf hin, dass hier erhebliche Verbesserungspotenziale zu verwirklichen sind:

OCR Vergleich Tesseract 4.1 und Calamari
Um die mit diesen OCR-Modellen erzielbare OCR-Qualität präzise und reproduzierbar automatisch zu bestimmen, wurde zudem das Evaluationstool Dinglehopper entwickelt, das es erlaubt OCR Ergebnisse in den Formaten ALTO, PAGE-XML und Text mit Referenzdaten (sog. Ground Truth) zu vergleichen und die Differenzen visuell darzustellen. Zudem wurden gegenüber anderen frei verfügbaren Werkzeugen für die OCR Evaluation einige Verbesserungen bei der Behandlung von Sonderzeichen (Ligaturen, Umlaute, Sonderzeichen) vorgenommen.
Strukturerkennung
Die mit Dinglehopper bislang durchgeführten Evaluierungen deuten weiter darauf hin, dass noch auftretende Fehler bei der Texterkennung häufig auf Fehler im Bereich der Layoutanalyse und Textzeilenextraktion (moderne OCR Verfahren arbeiten mit Textzeilen als Input) zurückzuführen sind. Daher arbeitet die SBB auch an einem speziell auf die vielfältigen in historischen Dokumenten auftretenden Layouts trainierten Tool für die Strukturerkennung. Ziel ist es dabei, ausgehend von einer grundlegenden Layoutanalyse einer Dokumentenseite alle Regionen zu ermitteln, die nur Text enthalten (z.B. Absätze, Blöcke) und von weiteren Regionen wie bspw. Grafiken (Abbildungen, Illustrationen, Photographien) oder sonstigen Strukturen (Tabellen, Diagramme) zu unterscheiden. Hierfür wurde in einem ersten Schritt eine Layoutanalyse basierend auf den Konvolutionalen Neuronalen Netzen (CNN) ResNet (He et al., 2015) und U-Net (Ronneberger et al., 2015) entwickelt. Ausgehend von zuvor manuell annotierten Trainingsdaten lernen die Neuronalen Netze hierbei für jedes einzelne Pixel zu entscheiden, in welche übergeordnete Strukturklasse sich dieses am besten zuordnen lässt.
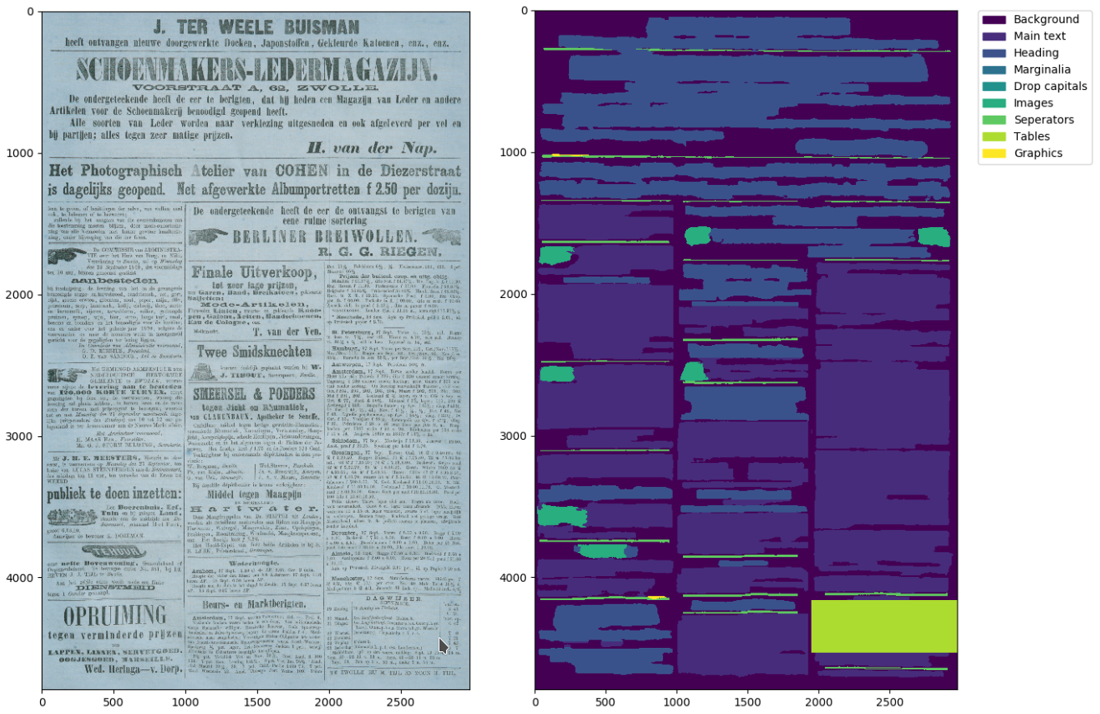
Layoutanalyse mit ResNet/U-Net
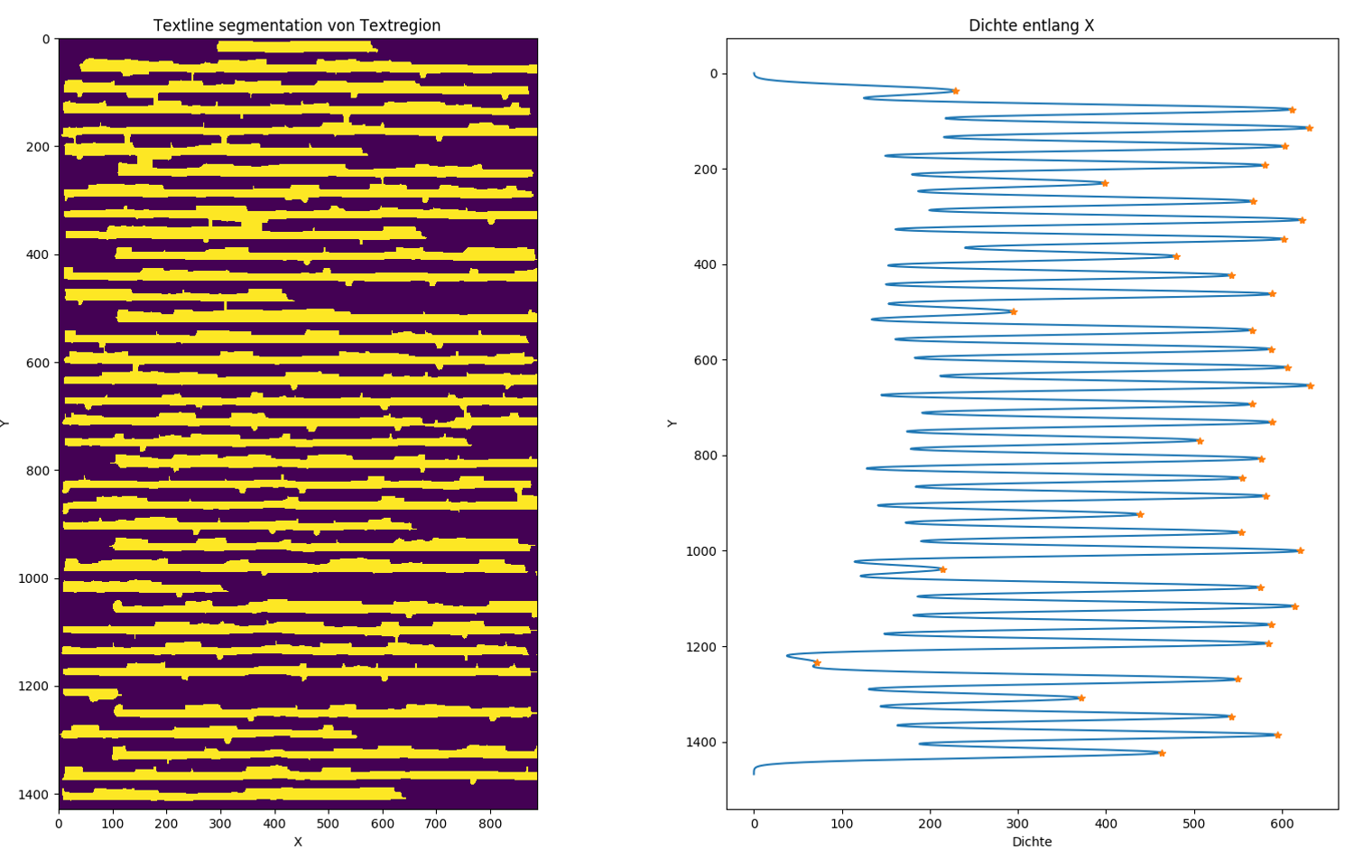
Textzeilenerkennung
Auf der Basis der so erkannten Bildregionen die Text enthalten werden in einem weiteren Schritt schließlich anhand der Dichte der Pixel entlang der x-Achse einzelne Zeilen erkannt und für die Texterkennung durch eine OCR-Engine extrahiert.
Die bislang erzielten Ergebnisse sind bei einer ersten rein qualitativen Betrachtung dem state-of-the-art überlegen. Um dies jedoch systematisch und quantitativ zu evaluieren, wird angestrebt in 2020 – erneut in Kooperation mit dem OCR-D Projekt – eine freie Version der Layoutevaluation von PRImA (Clausner et al., 2011) zu implementieren.
Named Entity Recognition
Sind erst einmal die größten Herausforderungen der Text- und Strukturerkennung mit zufriedenstellender Qualität bewältigt, so steht einer weiteren Analyse und Anreicherung der digitalisierten Dokumente mit semantischen Informationen nichts mehr im Wege. Eine häufige Anwendung ist hier z.B. die Eigennamenerkennung (Named Entity Recognition, NER). Unter NER versteht man die Erkennung von Namen für (üblicherweise) Personen, Orte und Organisationen aus Texten.
Scheint dies im ersten Moment noch recht trivial, so ergeben sich bei genauerer Betrachtung doch erhebliche Schwierigkeiten: so müssen durch ein geeignetes NER Verfahren nicht nur historische Schreibvarianten („Leypzick“ –> „Leipzig“) korrekt zugeordnet werden sondern dieses auch robust gegenüber den (hoffentlich wenigen) verbleibenden OCR Fehlern („Lcipzlg“ –> „Leipzig“) sein. Zudem ist die Zuordnung eines Namen zu einer Kategorie nicht immer so eindeutig, wie es auf den ersten Blick scheinen mag. Nehmen wir z.B. den Satz „Paris ist schön“, so könnte mit „Paris“ sowohl die Stadt Paris als auch die Person Paris Hilton gemeint sein. Ein gutes NER Verfahren muss daher also auch immer den Kontext mit in Betracht ziehen.

Beispiel Ausgabe der NER auf OCR Volltext
Für die Entwicklung eines für all diese Anforderungen geeigneten NER Tools hat sich die SBB entschieden, auf BERT (Devlin et al., 2018) aufzubauen. BERT hat nicht wirklich etwas mit der Sesamstraße zu tun – vielmehr steht BERT für Bidirectional Encoder Representations from Transformers, ein von Google Ende 2018 veröffentlichtes Neuronales Netz, das darauf trainiert wurde, grundlegende Merkmale natürlicher Sprache zu lernen.
Ausgehend von Google’s BERT Modell hat die SBB dieses zuerst mit einem Datenset aus großen Mengen von deutschsprachigen Volltexten der digitalisierten Sammlungen (Labusch et al., 2019) so trainiert, dass das Modell auch die Besonderheiten von historischen deutschen Schreibweisen erlernt. In einem weiteren Schritt bekam das Modell dann kleinere Mengen von manuell annotierten Daten (Neudecker, 2016) vorgelegt, also Dokumente in denen manuell Personen, Orte und Organisationen vorab markiert wurden, um diese in den digitalisierten Sammlungen automatisch erkennen zu lernen.
Die entwickelte Methode und quantitative Evaluation des so trainierten Modells gegenüber der state-of-the-art in einer Reihe von Experimenten wurde auch in einem Konferenzbeitrag auf der KONVENS2019 vorgestellt. Dabei zeigte sich, dass das so gewonnene Modell die Qualität der NER im Vergleich zu den bislang verfügbaren generischen Methoden (Riedl et al., 2018) erheblich steigert (f1-score von 84.3% vs. 78.5%) bzw. ohne weiteres Fine-tuning die Qualität von speziell angepassten Lösungen (Schweter et al., 2019) erreichen kann.
Um die Qualität der NER weiter zu steigern wurde zudem das Annotationstool neath entwickelt, mit dem aktuell in Kooperation mit dem DFG-Projekt SoNAR-IDH weitere Trainingsdaten erstellt werden. Aktuell wird auch an der Disambiguierung erkannter Entitäten sowie der Zuordnung zu und Verlinkung mit einer Normdatei wie der Gemeinsamen Normdatei (GND) der Deutschen Nationalbibliothek oder Wikidata mittels Contextual String Embeddings (Akbik et al., 2018) gearbeitet.
Sämtliche der genannten und von der SBB im Rahmen von QURATOR entwickelten Software-Tools werden über GitHub als Open Source veröffentlicht. Die trainierten Modelle und dazu verwendeten Datensets werden zudem auch sukzessive im SBB Lab veröffentlicht.
Sollte all dies ihr Interesse geweckt haben, bleibt nur noch der Hinweis auf die #QURATOR2020 Konferenz am 20-21 Januar 2020 in Berlin, wo neben der SBB auch die weiteren Projektpartner von QURATOR sowie eine Reihe von KI-Expert*innen und Anwender*innen die neuesten innovativen Verfahren für die Digitale Kuratierung mit künstlicher Intelligenz präsentieren werden.
Vorschau: In unserem nächsten Beitrag wird es kämpferisch – wir beleuchten den Einsatz von KI im Militärwesen!

 Susanne Henschel
Susanne Henschel
 DFKI
DFKI



 Staatsbibliothek zu Berlin - PK
Staatsbibliothek zu Berlin - PK
Ihr Kommentar
An Diskussion beteiligen?Hinterlassen Sie uns einen Kommentar!